Einführung: Schnittstelle Kommandozeile Teil 10
von Peter Kelly (critter)
Mit der Veröffentlichung des UNIX Betriebssystems in den frühen 70ern stand endlich ein solides Betriebssystem zusammen mit einem Satz Werkzeuge (Hilfsprogramme, tools), die zur Nutzung seiner fortgeschrittenen Eigenschaften programmiert worden waren, zur Verfügung. Das System wurde von der Gemeinschaft der Computernutzer begrüßt und einige der Werkzeuge (tools) fanden reges Interesse. Einerseits erlaubte die von Dennis Ritchie entwickelte Programmiersprache C eine schnelle Entwicklung des Systems und der Werkzeuge. Andererseits war sed, der stream Editor verfügbar. Wegen des großen Interesses für sed und einige der anderen Werkzeuge zur Textmanipulation beschlossen 3 Ingenieure von Bell Laboratories eine Programmiersprache zu entwickeln, die die Arbeit, die mit diesen tools bewerkstelligt wurde, verfeinern und vereinfachen sollte. Sie wurde 1977 unter dem Namen awk veröffentlicht. Letzterer leitet sich aus den Initialen der drei Entwickler ab, Alfred Aho, Peter Weinberg und Brian Kernighan. Brian hatte schon mit Dennis Ritchie an der Programmiersprache C gearbeitet und vieles von den C Strukturen findet man auch in awk. (Die ursprüngliche C Programmiersprache kennt man auch heute noch als K & R C).
Awk war geschrieben worden, um schnelle und schmutzige Befehle zum Extrahieren und Reformatieren von Textzeilen zu ermöglichen. Zur Überraschung der Autoren wurde das Programm bereits Mitte der 1980er so viel genutzt, dass es überarbeitet wurde und den Namen nawk (new awk) erhielt. Es wurde viel Programmfunktionalität zugefügt und so wurde es zu dem Scripting Werkzeug, das wir heute anwenden. Linux Nutzer haben wahrscheinlich gawk. Dieses ist nawk so ähnlich, dass es für die meisten Nutzer keinen Unterschied macht.
Sie werden awk als 'awk' oder 'AWK' geschrieben finden. Es besteht eine allgemeine Übereinkunft darüber, dass man unter awk das Interpreterprogramm versteht und dass mit AWK die Scriptsprache, die in den Scripten verwendet wird, gemeint ist.
AWK
Einer der Entwickler, Alfred Aho, beschreibt awk wie folgt:
"AWK ist eine (Computer)Sprache für das Bearbeiten von Textdateien. Eine Datei wird als Aufeinanderfolge von Datensätzen angesehen. Standardmäßig stellt jede Zeile einen Datensatz dar. Jede Zeile wird in eine Abfolge von Feldern umgebrochen, wir können uns das erste Wort der Zeile als das erste Feld vorstellen, das zweite als das zweite Feld usw. Ein AWK Programm besteht aus einer Folge von Statements zur Musterbearbeitung. Als Eingabe liest AWK Zeile um Zeile. Die Zeile wird nach jedem Muster des Programms durchsucht. Bei jeder Musterübereinstimmung werden die dazugehörigen Aktionen ausgeführt."
Das fasst ganz gut zusammen, was es macht, aber es beschreibt bei Weitem nicht die Mächtigkeit und Flexibilität der Sprache. Das werden wir noch sehen.
Awk zu benutzen muss nicht kompliziert sein. Es kann sich dabei um einen einfachen Einzeilenbefehl handeln, der über die Konsole eingegeben wird. awk '{ print $1 }' test würde das erste Wort oder 'Feld' jeder Zeile der Datei Test ausgeben. Die Variablen $1, $2 ... usw. werden den entsprechenden Felder eines Datensatzes zugeordnet. Die Variable $0 enthält den gesamten Zeileninput/Datensatz, NF die Anzahl der Felder des gegenwärtigen Datensatzes und NR den Zahlindex des gegenwärtigen Datensatzes.
Wir sollten hier eine Pause machen und uns darüber klar werden, woran wir arbeiten.
Ein 'Wort', auch 'Feld' genannt ist nicht nur ein Wort aus einer Sprache. Es handelt sich dabei vielmehr um eine Aufeinanderfolge von Zeichen, die durch ein Leerzeichen (white space) oder ein Zeichen für eine neue Zeile beendet wird. Durch das Leerzeichen white space werden die Felder standardmäßig getrennt. Es handelt sich dabei um ein oder mehrere Leerzeichen oder Tabulatoren. Mit der -F Option kann das Standardtrennzeichen über die Kommandozeile in jedes beliebige Zeichen umgewandelt werden. In einem Script geschieht das durch Setzen der Variable FS. awk -F":" '{print $1}' /etc/passwd ändert das Standardtrennzeichen zu einem Doppelpunkt und gibt das erste Feld jeder Zeile der Datei /etc/passwd aus. Wir erhalten also eine Liste aller Nutzer des Systems, die einen Namen haben.
Ein Datensatz besteht aus einer Gruppe von Feldern und kann als eine Karteikarte in einem indizierten Karteikartensystem angesehen werden. Die Daten auf der Karteikarte können Einzelheiten eines Directorylistings sein, ein Satz von Werten, die aus irgendeinem Test resultieren oder, wie wir gesehen haben, eine Zeile aus der Systemdatei /etc/passwd. Die Variable RS enthält das Datensatztrennzeichen. Standardmäßig ist das das Zeichen für neue Zeile \n. Eine Änderung des Wertes von RS erlaubt es uns mit mehrzeiligen Datensätzen zu arbeiten.
Die Syntax zur Verwendung des awk Befehls auf der Kommandozeile sieht wie folgt aus:
awk {options}{pattern}{commands}
Dabei gibt es für awk folgende Optionen:
-F zum Ändern des Feldtrennzeichens -f zur Festlegung des zu verwendenden Scriptnamens -v zur Festlegung des Wertes einer Variablen.
Wir hätten also zur Änderung des Feldtrennzeichens -v FS=":" verwenden können.
Es gibt noch einige andere (Optionen), aber da awk hauptsächlich in Scripten verwendet wird, werden sie selten benutzt.
Muster ist, wie in sed ein optionaler regulärer Ausdruck zwischen zwei einfache Anführungszeichen gesetzt. Wenn er nicht gesetzt ist, werden die Befehle auf die gesamte Zeile angewendet.
Befehle sind auch optional und, wenn nicht gesetzt, wird jede Zeile, die mit Muster übereinstimmt, vollständig und unverändert ausgegeben.
Wenn Sie beides, Befehle und Muster nicht setzen, erhalten Sie eine Erinnerung an die Benutzung (von awk), das haben Sie dann auch verdient.
Die Nutzung von awk in einem Shell Script ist so ziemlich die gleiche, wie die über die Kommandozeile.
Ein awk Script kann auf zwei verschiedene Arten aufgerufen werden.
1. Erzeugen Sie eine Scriptdatei mit dem Namen awkscript oder wie auch immer:
{
FS=":"
print $1" uid="$3
}
Rufen Sie es mit der -f Option auf: awk -f awkscript /etc/passwd
2. Als erste Zeile des Scripts fügen Sie folgende Zeile hinzu:
#!/bin/awk -f
Ich gebe Dateien wie dieser einen 'awkischen' Namen — uid.awk.
Machen Sie sie ausführbar; chmod +x uid.awk. und rufen Sie sie mit ./uid.awk /etc/passwd auf. Die #! Zeile muss die aktuelle Adresse der ausführbaren awk Datei enthalten. Diese können Sie mit dem Befehl which awk überprüfen.
Nun, wenn Sie mit Linux arbeiten ist awk höchstwahrscheinlich ein symbolischer Link zu gwak, die gnu Version von awk. Die hat noch einige Extras, aber alles wird mit beiden Versionen funktionieren, es sei denn, es wird anderweitig erklärt. Wenn Sie wissen wollen, welche (Version) Sie nutzen, erfahren Sie es mit dem Befehl awk --version.
Bei dem Script, das wir gerade erzeugt haben wird alles, was zwischen den geschwungenen Klammern steht, einmal an jeder Zeile der Ausgangsdatei oder an jedem Datensatz durchgeführt. Wir können auch eine 'Kopfzeile (header)' und eine 'Fusszeile (footer)' einführen. Diese kennt man als BEGIN und END Blöcke. Dazwischen können wir Code einfügen, von dem wir wollen, dass er nur einmal – am Anfang oder am Ende der Abarbeitung des Scripts ausgeführt wird. Beim BEGIN Block initialisieren wir normalerweise Variablen wie FS, den END Block können wir zur Ausgabe einer Abschlussmeldung benutzen oder zur Ausgabe einer Zusammenfassung abgearbeiteter Befehle.
Das Script hat dann drei Abschnitte:
BEGIN{
commands}
{ command
|
This is the main part of the script
|
command}
END{
commands}
Alle Abschnitte sind optional, wobei es ziemlich sinnlos wäre nicht zumindest einen zu setzen. Das folgende Codebeispiel gibt den Namen aller Systemnutzer aus, die die Bash als Standardshell nutzen.

Beachten Sie, dass die Slashs (dem Befehl) entzogen werden müssen. Für das Gleichheitssymbol habe ich hier zwei Gleichheitszeichen verwendet, bei awk kann aber auch das Tildesymbol ~ zur Übereinstimmungsprüfung mit regulären Ausdrücken verwendet werden. In der Regel nutzen wir sie als Abkürzung für unser Heimatverzeichnis.
Aber was macht es?
Nun, es verarbeitet Text und sonstige Daten.
Ja, das macht sed (auch), aber wenn Sie sed mit seinen Suchen und Ersetzen Funktionen für Textverarbeitung gemocht haben, dann können Sie jetzt mit awk die Programmierfähigkeiten einer hoch entwickelten Sprache wie C, Fliesskommaberechnungen einschließlich Trigonometrie- und Exponentialfunktionen, Funktionen zur Stringmanipulation, Benutzerdefinierte Funktionen, Datenauszüge, bool'sche Operatoren und multidimensionale und assoziative Felder hinzurechnen. Unix/Linux Befehle erzeugen oft tabellarische Testausgaben und awk ist das ideale Werkzeug, um aus dieser Datenart Berichte zu erzeugen. Dabei werden ganz einfach eine Kopfzeile, Bereiche für Auswahl und Manipulation und ein Schlussbereich zur Berechnung der Ausgaben und einer Zusammenfassung bereitgestellt.
Kurz, awk ist ein Berichtsgenerator und eine fortgeschrittene Scriptsprache, die fast alles macht, obwohl sie ohne ernsthafte Veränderungen an der Hardware letztlich doch nicht Ihren Kaffee kochen wird.
Man sollte annehmen, dass das Erlernen des Gebrauchs eines so komplexen Programms wie awk einer Bergbesteigung ähnelt, aber das ist glücklicherweise nicht der Fall. Wenn Sie (unserem Kurs) Shellscripting, reguläre Ausdrücke und sed mitgemacht haben, dann haben Sie schon das meiste der Schwerarbeit geleistet. Es gibt einige Unterschiede, aber nichts, was Ihr Gehirn anstrengen würde.
Einfache awk Scripts
Obwohl man awk über die Kommandozeile nutzen kann und das auch oft geschieht, wird es am nützlichsten, wenn man es in einem Script anwendet. Das Script kann man speichern und es kann leicht verändert werden, um andere oder ähnliche Aufgaben durchzuführen.
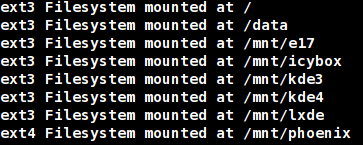
Nehmen wir an, wir wollten wissen, welche ext Dateisysteme in /etc/fstab gelistet sind und wo diese eingebunden (gemountet) sind. Das geht mit awk ganz einfach, indem man eine konditionelle if Bedingung nutzt. Ich habe hier eine verschachtelte Bedingung benutzt, um sicher zu sein, dass Kommentare ausgeschlossen werden.

Das bedeutet: wenn das erste Feld nicht mit einem # beginnt, dann, wenn das dritte Feld "ext" gefolgt von einem anderen Buchstaben enthält, dann soll der Typ des Dateisystems und sein Einhängepunkt ausgegeben werden.
Nachstehend finden Sie die Ausgabe meiner Maschine als Resultat des Befehls:./awk1.awk /etc/fstab.
awk wird oft als Alternative zu sed angesehen und tatsächlich kann es auch so genutzt werden. Was immer Sie benutzen hängt davon ab, was Sie machen möchten. Erinnern Sie sich an die Quälerei, die wir bei sed hatten, um Größe, umformatiertes Datum und Dateinamen einer Verzeichnisliste auszugeben.?
sed -n -e 's/M/ MegaBytes/' -e 's/-.\{12\}\(.\..
MegaBytes\) \([0-9]\{4\}\)-\([0-9][0-9]\)-\([0-9][0-9]\)
..:.. \(.*$\)/\4\/\3\/\2 \1 \5/p' sed-demo
In einem awk Script können wir damit anfangen, nur Datensätze (Zeilen) in Betracht zu ziehen die:

mit einem Hyphen beginnen (Zeile 3) und aus 6 Feldern bestehen (Zeile 4). In Zeile 5 binden wir die Funktion sub() ein. Diese ersetzt das M im dritten Feld durch "MegaBytes".
In Zeile 6 rufen wir eine andere eingebaute Funktion mit dem Namen split() auf. Diese splittet das vierte Feld - das Datumsfeld – unter Benutzung eines Hyphen als Feldtrennzeichen auf und speichert jeden Teil als Element eines Arrays (Feld) mit dem Namen fdate.
Zeile 7 beschränkt die Anwendung auf nur die Zeilen, deren drittes Feld mit "BYTES" endet.
Zeile 8 gibt das umformatierte Datum, gefolgt von Dateinamen- und Größe, aus, indem es die Elemente vom Array (Datenfeld) holt.
Selbst wenn das Script eine Menge Material enthält, das Sie noch nie gesehen haben, so denke ich doch dass es weniger entmutigend ist als seine sed Entsprechung. Die Ausgabe ist die Gleiche.
Natürlich kann awk auch von einem Script aufgerufen werden und tatsächlich nutzen viele Systemscripte awk auf umfassende Weise. Ein wichtiges Konzept muss berücksichtigt werden, wenn man awk aus einem Shell Script aus aufrufen will. In einem Shell Script weist das $ Zeichen auf eine Variable hin wie z. B. $USER. Dagegen bezieht es ($) sich in awk auf ein Feld, wie $2 womit das 2. te Feld eines Datensatzes gemeint ist.
Wenn Sie awk in einer Shell aufrufen, müssen die Befehle in einfache Anführungszeichen gesetzt werden, um sie vor der Shellerweiterung zu schützen. Wenn Sie awk den Befehl '{ print $USER }' übergeben und erwarten, dass so wie beim Shell echo Befehl, der Benutzername ausgegeben wird, dann werden Sie eine Überraschung erleben.
Awk sieht dann nicht eine Variable, sondern eine Referenz auf den Feldindex 'USER'. Da USER nicht definiert ist, hat er den Wert 0, es ergibt also $0, was bedeutet, dass der gesamte Datensatz ausgegeben wird.

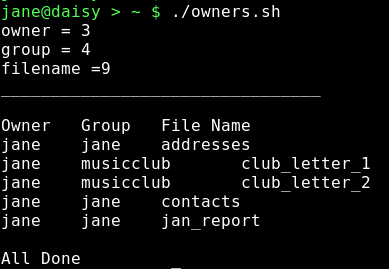
In diesem Bash Script leiten wir die Ausgabe eines Listings des Heimatverzeichnisses des Benutzers in einen awk Befehl um, welcher dann den Besitzer, die Gruppe und den Dateinamen jedes Eintrags ausgibt.
Im ersten Teil des Scripts werden den Variablen Werte zugewiesen. Diese werden mit echo am Bildschirm ausgegeben, um zu zeigen, welche Werte sie in diesem Teil des Scripts besitzen. Das Verzeichnislisting wird dann in den awk Befehl umgeleitet, der über einen BEGIN Teil zur Ausgabe eines Headers verfügt. Der Hauptteil besteht aus einem einzigen print Statement, das auf alle Eingabezeilen mit 8 Feldern wirkt. Der END Teil beendet den Report.
Die Syntaxhervorhebung zeigt, wie die wörtliche Wiedergabe ein- und ausgeschaltet wird, um Shellerweiterung zuzulassen, oder nicht.
Jede nicht in Anführungszeichen gesetzte Variable wird auf ihren Wert erweitert. So wird aus print $'$owner' print $3 (das dritte Feld). Zwei $Zeichen sind notwendig, da $owner nur als 3 gesehen wird. Beim \t im Befehl handelt es sich um ein Tabulatorzeichen.
Die Mächtigkeit, die awk zur Verfügung stellt, wird durch die eingebauten Funktionen, wie im Script verwendet demonstriert. Wir sollten daher einen Blick auf die Funktionen werfen, die zur Verfügung stehen und darauf, was sie bewirken und wie man sie aufruft.
Die in awk eingebauten Funktionen lassen sich in 3 Gruppen aufteilen.
- Funktionen zur Textmanipulation
- Numerische Funktionen
- Funktionen zur Dateimanipulation
Mit den awk Funktionen zur Dateimanipulation sollte man sich nicht abgeben. Verwenden Sie irgend etwas anderes, wann immer es möglich ist. Wenn Sie Dateien öffnen oder schließen wollen, dann rufen Sie den awk Befehl aus einem Shell Script heraus auf und lassen Sie die Shell die Kontrolle der Dateien übernehmen. Shells verfügen über ein exzellentes Handling von Dateien.
Awk´ s eigene Funktionen zur Numerik von Ganzzahlen sind recht vollständig und sollten die Bedürfnisse der Meisten befriedigen. Wenn Sie sie brauchen, sind die Fliesskommaoperationen von awk auch recht gut. Man kann sie auch als Umgehung der Shell, die damit nicht umgehen kann nutzen, aber denken Sie daran, dass der Wert der Shell als ein String zurückgegeben werden muss. Für mich haben diese awk Funktionen wenig Nutzen, obwohl ich in meiner täglichen Arbeit viel mit Mathematik zu tun habe. Dafür gibt es bessere Werkzeuge. Sie würden ja auch einen Brief nicht mit einem Tabellenkalkulationsprogramm schreiben, obwohl das möglich wäre.
Das was awk wirklich bietet sind Funktionen zur Textmanipulation. Beginnen wir also damit.
Eine häufige Aufgabe ist Substitution und awk stellt 3 Funktionen bereit um dies zu bewerkstelligen:
sub() und gsub(). Diese Befehle sind analog zum s Befehl in sed und zum s Befehl mit der g (global) Option.
gensub() Hier handelt es sich um eine allgemeine Substitutionsfunktion in gwak. Im originalen awk gibt es sie nicht. Achten Sie darauf, wenn Ihr Code portierbar sein soll.
Die ersten beiden Funktionen werden mit sub(/regexp/,Ersetzung, Suchfeld) aufgerufen. Das bedeutet "ersetze (womit dies auch immer übereinstimmt, hiermit, dorthin)."
Im dorthin Teil wird die Übereinstimmung gesucht. Er kann eine Variable sein ($myvar)eine Feldreferenz ($1) oder ein Feldelement (array[1]). Wenn dieser Teil nicht angegeben ist, wird $0 (also der gesamte Datensatz) durchsucht. Beachten Sie, dass Sie eine Fehlermeldung erhalten, wenn Sie das Suchfeld nicht angeben und das zweite Komma nicht entfernen.
Damit können Sie jetzt ganz leicht ein ganz bestimmtes Muster ersetzen und mehrfache Übereinstimmungen in einem Datensatz sind möglich.
Die gsub() Funktion arbeitet auf dieselbe Weise mit dem Suchfeld. Das 'globale' Ersetzen ist auf einen bestimmten Teil des Datensatzes beschränkt. Die Funktion gensub() wird so aufgerufen: gensub(/regexp/, Ersatz, auf welche Art, Suchfeld).
Neu ist der Parameter auf welche Art. Wenn dieser g oder G ist, werden alle Übereinstimmungen ersetzt. Wenn es sich um eine Zahl handelt, wird nur die Übereinstimmung ersetzt, die hierdurch gekennzeichnet ist. sub() und gsub() ändern die Originalzeichenketten bei ihrem Durchlauf. Wir haben das bei unserem ersten kleinen Script gezeigt, bei dem 'M' durch 'MegaBytes' ersetzt wurde. (Es wird die Zeichenkette oder der Datensatz ersetzt, nicht die Ausgangsdatei). gensub() verändert die ursprüngliche Zeichenkette nicht, sondern sie wird als Ergebnis der Funktion zurückgegeben. Man muss also eine Zuordnung vornehmen um die Änderungen nutzen zu können.

Dies ändert das erste Auftreten der Zeichenkette "jane" in "me" und übergibt das Ergebnis an die Variable "owner". Da jane erstmalig im dritten Feld der Dateiliste erscheint sehen wir, dass der Eigner tatsächlich "me" ist, wogegen das ursprüngliche Feld $3 unverändert bleibt, wie man an der Ausgabe von $0, dem ursprünglichen Eingabedatensatz entnehmen kann.

Folgendermaßen kann die Zuweisung des Ergebnisses einer Funktion an eine Variable stattdessen auch direkt an einen Ausgabebefehl übergeben werden:
print gensub(/jane/, "me", "1" )
Eine andere Funktion, die wir im ersten Beispiel verwendet haben istsplit(). Es handelt sich dabei um ein außerordentlich bequemes Werkzeug.
Split( string_to_split, name_of_an_array, separator )
Es greift sich einen String, der im ersten Parameter spezifiziert ist, sucht danach, wie das Trennzeichen, im dritten Parameter angegeben, aussieht und speichert jeden getrennten Brocken als ein Element des im zweiten Parameter spezifizierten Feldes. Das Trennzeichen kann ein einzelner Buchstabe sein oder ein regulärer Ausdruck. Wenn es nicht im Befehl angeführt ist, wird der aktuelle Wert der awk Variablen FS verwendet. Handelt es sich dabei um einen leeren String "", so wird jedes einzelne Zeichen als getrenntes Feldelement gespeichert. Beim von der Funktion zurückgegebenen Wert handelt es sich um die Anzahl der Feldelemente.
Dies eignet sich hervorragend für Aufgaben wie Namen- und Adressverarbeitung oder für die Umwandlung numerischer Daten in ihre Textäquivalente.
Im (folgenden) Beispiel geben wir in ein Script ein Datum in numerischer Form und durch Leerzeichen getrennt ein. In der Ausgabe wird der Monat in Textform angezeigt.
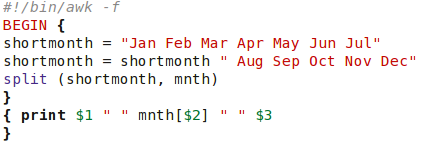
Am BEGIN Teil des Scripts werden die Monate in ein Feld vorgeladen. Die zweite Zuweisungsbedingung benötigt am Anfang ein trennendes Leerzeichen, andernfalls würden wir einen Monat 'JulAug' erhalten. In der zweiten Zuweisungsbedingung findet man darüber hinaus ein weiteres Merkmal von awk. Es ist das die Verkettung zwischen dem Variablennamen und dem String der durch Einfügen eines Leerzeichens damit verknüpft werden soll.

length() hübsch und einfach length( string)
Dies gibt einfach die Länge des übermittelten Strings zurück, oder, wenn kein String spezifiziert ist, die Länge der aktuellen Zeile $0.
substr() substr( string, start-position, max_length )
Diese Funktion gibt den sub-string zurück, der bei start_position anfängt und erweitert ihn auf die Anzahl von max_length Zeichen oder das Stringende. Die Funktion gibt den gefundenen sub-string zurück. Sie kann nicht für Veränderungen von Teilen des Strings verwendet werden. Verwenden Sie dafür sub().
Diese Funktionen können auch auf der Kommandozeile verwendet werden, obwohl man sie gewöhnlich eher in Scripts findet. Um den Kommandozeilengebrauch zu demonstrieren übermitteln wir über eine pipe die Ausgabe des uname -r Befehls (gibt die aktuelle Kernelversion aus) an awk. Dann verwenden wir die substr() Funktion, um nur einen Teil der Ausgabe zu finden und diesen Teil am Bildschirm auszugeben.

Zum Auffinden der Position eines sub-strings in einem String stellt awk die Funktion index() bereit.
index( string, substring )
Der zurückgegebene Wert ist die Anfangsposition des sub-strings oder 0, wenn er nicht gefunden wird.


Wir finden den Beginn der Prozessorbeschreibung und benutzen dann den zurückgegebenen Wert, um von dort aus bis zum Zeilenende einen sub-string auszuschneiden. Auf diese Weise brauchen wir die Anzahl der Worte in der Beschreibung nicht zu kennen.
Eine ähnliche Funktion ist match().
match( string, regular_expression )
Anstatt einen einfachen String zu suchen, bedient sich die match() Funktion der viel mächtigeren Musterübereinstimmung mit regulären Ausdrücken. Der zurückgegebene Wert, wie index(), ist die Anfangsposition der Übereinstimmung. Darüber hinaus setzt diese Funktion zwei weitere Variablen von awk: RSTART & RLENGTH
Hier haben wir eine Datei, die wir ganz am Anfang dieses Kurses erzeugt haben:

Wenn wir uns den Anfang des Zeitstrings in der zweiten Zeile anschauen,

dann erhalten dieses Resultat, weil nur die zweite Zeile eine Überstimmung enthielt.

Etwas, was wir oft ausführen wollen, ist Stringzeichen von Großbuchstaben in Kleinbuchstaben umzuwandeln und umgekehrt.
Awk verfügt über ein Funktionspaar, mit dem dieser Prozess automatisiert werden kann. Sie heißen, wohl wenig überraschend, toupper() und tolower(). Jeder (dieser Befehle) übernimmt einen einzelnen String als Argument und gibt eine Kopie davon zurück, wobei alle Zeichen umgewandelt wurden (von groß auf klein und umgekehrt).
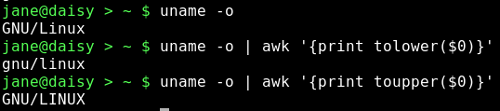
Was könnte einfacher sein?
Für Text muss ich die sprintf() Funktion anführen.
Diese Funktion arbeitet genauso wie die printf() Funktion, die wir beim Scripting der Bash Shell benutzt haben, mit dem Unterschied, dass diese hier den Text nicht ausgibt. Sie gibt eine formatierte Kopie des Textes aus. Dies ist höchst hilfreich und wird dazu benutzt hübsch formatierte Textdateien zu erstellen, bei denen die Felder eines Datensatzes von unbestimmter Größe sind.
Sie haben wahrscheinlich bemerkt, dass die Ausgabe des owners.sh Script, das wir benutzt haben, um Variablenübergabe in Shell Scripten zu demonstrieren, unordentlich und zerrissen war. Wenn wir an Stelle des einfacheren print Befehls das printf statement benutzen, können wir genau angeben, wie der Bericht aussehen soll.


Die Regeln zur Formatierung sind die gleichen und den Feldern, die ausgegeben werden sollen, kann eine festgelegte Breite vorgegeben werden oder ein vordefiniertes Zahlenformat oder die Anzahl der Dezimalziffern, wenn es sich um Zahlenfelder handelt. Die Unterdrückung von führenden und nachfolgenden Nullen wird ebenso unterstützt, wie das Auffüllen von kürzeren Feldern mit Leerzeichen oder Nullen, je nachdem, was nötig ist. Tatsächlich werden bei awk alle Variablen als Strings gespeichert. Variablen mit numerischen Werten können trotzdem in arithmetrischen Funktionen und Berechnungen verwendet werden.
Eine hübsche Eigenschaft von awk ist es, dass die Felder assoziativ sind. Das bedeutet, dass ein Feld aus einer Paargruppe besteht, - dem Wert und einem Index. Der Index muss nicht, wie in den meisten Programmiersprachen, eine Ganzzahl sein. Er kann auch ein String sein. Dabei ist die Reihenfolge unwichtig, obwohl Sie Zahlen verwenden können um Elemente eines Feldes zu indizieren. Der Zahlenwert hat in awk keine Bedeutung, sondern lediglich, dass er mit einem bestimmten Wert assoziiert ist.
Dies macht die Felder bei awk ausgesprochen flexibel und effizient. Bei den meisten Programmiersprachen müssen Felder sowohl hinsichtlich des Wertetyps, der verwendet werden soll deklariert werden, als auch hinsichtlich der maximalen Anzahl ihrer Elemente. Danach wird dann ein Speicherblock für dieses Feld reserviert und zugewiesen und Typ und Größe können nicht verändert werden. awk kümmert sich dagegen um nichts von alledem. Die Indices können Sie wählen als was immer Sie wollen. Die gespeicherten Werte können irgendeine Mischung aus dem sein, was Sie sich wünschen und Sie können so viele Elemente hinzufügen, wie Sie wollen.
Besonders nützlich sind assoziative Felder beim Durchsuchen von Tabellen. Nehmen wir an, Sie haben eine Textdatei mit Namen phonetic und folgendem Inhalt:
a Alpha b Bravo c Charlie : : y Yankee z Zulu
Die können wir in ein assoziatives Feld einlesen und das Feld dazu benutzen, die Buchstaben in ihre phonetischen Äquivalente umzuwandeln.


Wenn Sie das Gefühl haben, dass Ihnen die awk – eigenen Funktionen immer noch nicht genügen, oder wenn Sie feststellen, dass Sie wiederholt den gleichen Code erzeugen, dann sollte Sie nichts davon abhalten, Ihre eigenen Funktionen zu generieren.
Funktionen müssen im Vorfeld irgendwelchen Codes, der sie nutzen will deklariert werden. Das ist eigentlich ziemlich selbstverständlich, aber sie müssen aber auch vor dem Codeblock, der sie aufruft, stehen. Aus diesem Grund sollte der Code der Funktion normalerweise außerhalb und vor der Hauptschleife geschrieben sein.
Funktionsdeklarationen haben folgende Syntax: function function_name ( parameters ) {actions}. Das Schlüsselwort function ist verpflichtend.
function_name kann so ziemlich alles sein, was Sie wollen, mit Ausnahme eines reservierten Begriffs, eines Variablennamens oder eines Zeichenkettenmusters, das von awk fehlinterpretiert werden könnte. Es sollte auch mit einem Buchstaben oder einem Unterstrich beginnen.
parameters sind eine Liste von durch Kommas getrennte Variablen, die vom aufrufenden Code an die Funktion übergeben werden. Die Funktion verwendet die Parameternamen und diese müssen nicht dieselben sein, wie die Argumentenamen, die übergeben werden. Der Funktion wird nur der Wert übergeben. Trotzdem ist es in der Regel weniger verwirrend, wenn man die gleichen Namen beibehält.
Die actions, die innerhalb der geschweiften Klammern stehen werden von der Funktion an den übergebenen Parametern vorgenommen. Wenn ein return statement gesetzt ist, wird der Wert an den aufrufenden Code zurückgegeben.
Nehmen wir an, ein Script hat eine Funktion mit dem Namen myfunction mit dem Befehl result = myfunction( string) aufgerufen. Dann würde return newstring im Code der Funktion den Wert der Variablen newstring an die Variable result übergeben.
Wenn wir unser phonetics Script noch weiter nutzen wollen, indem wir ihm eine beliebige Suchliste übergeben sowie einen beliebigen String zur Übersetzung, dann können wir eine Funktion schreiben, die die Übersetzung durchführt.

Die Funktion erscheint vor der Hauptschleife und übergibt ihr 2 Parameter. Dabei ist c der zu übersetzende String und codes das Feld von Kleinbuchstaben und den ihnen zugeordneten phonetischen Codes. Durch die Benutzung eine leeren Strings als Feldtrennzeichen wird der String in einzelne Zeichen aufgespalten und dann in einem Feld mit Namen letters gespeichert. Man braucht die Länge des Strings, um die Schleife einzugrenzen. Diese läuft von eins bis zur Anzahl der Zeichen des Strings und gibt den Code aus, der zum aktuellen Buchstaben gehört.
In der Hauptschleife werden die Eingabedaten der phonetics Datei in den Code des Feldes eingelesen.
Im END Teil wird die Funktion aufgerufen und es wird ihr der String c übergeben, der seinerseits an die Kommandozeile weitergegeben wird und auch an das Codefeld.
Hier nochmal die Ausgabe eines Probedurchlaufs.
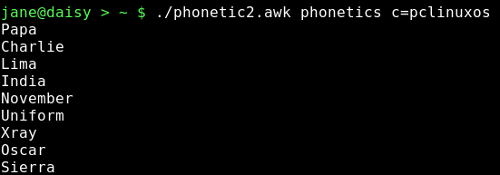
Wenn Sie mehrere verschiedene Datensätze haben unter denen Sie auswählen können wollen, ist es hilfreich, den Dateinamen über die Kommandozeile zu übergeben. Wenn es aber nur einen (Dateinamen) gibt, können wir ihn ins Script mit der getline Funktion von awk einlesen.

Im BEGIN Teil wird die Datendatei über eine while Schleife eingelesen, bis eine Leerzeile erreicht wird. Jede Zeile wird im Feld codes abgelegt. Der zu übersetzende String wird zu Beginn der Hauptschleife in Kleinbuchstaben umgewandelt. Im Kernbereich der Funktion wird eine Überprüfung mit einem regulären Ausdruck vorgenommen, um zu sehen, ob der Buchstabe aus dem Bereich a-z stammt. Wenn ja, wird umgewandelt. Wenn er nicht aus diesem Bereich stammt, wird er so, wie er ist ausgegeben, wobei die Anzahl der Leerzeichen, Zahlen und Interpunktion berücksichtigt werden. Die umzuwandelnden Strings können in ein Script überführt werden. Wie nachstehend gezeigt, können sie auch interaktiv auf der Kommandozeile eingegeben werden.
