Einführung: Schnittstelle Kommandozeile
Teil 9
von Peter Kelly (critter)
So ziemlich alles, was wir über die Kommandozeile bewirken, betrifft das Verändern, Vergleichen, Verschieben oder Löschen von Textdateien. Die Daten dazu können sich in einer Datei auf einer Festplatte befinden, oder sie können als Datenstrom die Ausgabe eines vorangehenden Befehls sein.
Bei den Bell Laboratories führte Ken Thomson bei der Entwicklung des UNIX Betriebssystems in den frühen 1970ern ein System ein, das Zwischenverbindungen von Datenströmen als Alternative zu Einzelprozessen erlaubte. Ken Thompson war wohl der Chefarchitekt dieses Projekts. Heute bezeichnen wir dieses System mit 'Pipes' und 'redirection'.
Damals, in dieser grauer Vorzeit, waren die Hilfsmittel dazu recht primitiv, sie haben aber überlebt und sich zu dem entwickelt, was wir heutzutage verwenden. Das Programm ed hat seither praktisch unverändert überlebt (und deswegen wird es heutzutage nur kaum noch genutzt). Anders als andere Texteditoren wie vi(m) ist ed ein Zeileneditor. Ein Zeileneditor liest eine Datei ein und bearbeitet jeweils eine Zeile und nicht die gesamte Datei. Sie verändern etwas in einer Zeile und gehen dann zur nächsten (oder zu einer anderen).
So einfach wie das Programm, waren auch die Befehle. Man benutzte p, um die Zeile im Terminal auszugeben und um zu sehen, was editiert wurde (das geht nicht automatisch), d, um eine Zeile zu löschen, s, um Text durch anderen auszutauschen, aber alles bezog sich nur auf diese Zeile. Um von Hand größere Textdateien interaktiv editieren zu können, bietet dies viel zu wenig Möglichkeiten. Daher wurden die Texteditoren, die wir heutzutage benutzen, entwickelt.
Für diese Art der nichtinteraktiven Zeileneditierung war die Einführung von pipes für Datenströme ideal. Daher wurde ein neues Hilfsmittel, der stream editor, entwickelt. Er liest Daten ein, und unterzieht sie währenddessen einer Reihe von Befehlen. Befehle wie Löschen, Ersetzen etc. können nun von der Kommandozeile kommen, oder von einem Script eingelesen werden. Wenn die Befehle von einer Datei kommen, wird diese nicht verändert. Es sind nur die Ausgangsdaten betroffen und das kann als neue Datei, oder in der Pipe weiterverarbeitet werden.
Sie haben vielleicht davon gehört, dass für dieses neue Hilfsmittel der ed Editor ausgewählt worden ist. Als Name wurde sed – stream editor gewählt.
SED
Das Hilfsmittel sed bewahrt eine Menge der Einfachheit, die es von ed geerbt hat, fügt aber eine Menge mehr an Funktionalität hinzu. Seine Befehlszeile oder Script kann auf den ersten Blick wie verwirrender Quatsch aussehen.
sed -n -e 's/M/ MegaBytes/;s/-.\{12\}\(.\.. MegaBytes\) \([0-9]\{4\}\)-\([0-9][0-9]\)-\([0-9][0-9]\) ..:.. \(.*$\)/\4\/\3\/\2 \1 \5/p' sed-demo
Wir können diesen 'Unsinn' in verständlichen Text übersetzen und dann werden die Dinge klarer. Es ist wirklich möglich, glauben Sie mir. Bevor Sie aber die Hände über dem Kopf zusammenschlagen und feststellen ''Das ist nichts für mich'', lassen Sie mich Ihnen sagen, dass es sehr unwahrscheinlich ist, dass Sie jemals ein so kompliziertes Befehlskonstrukt brauchen werden.
Hier sehen Sie etwas viel Einfacheres und Nützlicheres. Viele Linux Nutzer benutzen auch MS Windows. Wenn Sie versuchen eine unter Linux erstellte Textdatei in Windows auszulesen, dann werden Sie feststellen, dass die Zeilenumbrüche nicht funktionieren, sondern die Zeilen in voller Länge ausgegeben werden, was vom Zeileneditor (wahrscheinlich notepad) zugelassen ist,. Die Ursache dafür ist, dass in Linux Zeilen mit dem Zeichen \n beendet werden müssen, während DOS und Windows ein Zeilenendzeichen und ein carriage return benötigen \n\r (wie bei den alten Schreibmaschinen, wo das Papier um eine Zeile nach oben verschoben und der Druckkopf zum Zeilenanfang zurückgefahren wurde). Das Zeichen für eine neue Zeile alleine wird nicht als Zeilenende anerkannt. Solches kann mit sed leicht bearbeitet werden.
sed 's/$/\r/' linux-file > dos-file macht Linux Dateien unter DOS lesbar.
sed 's/\r//' /dos-file > linux-file verwandelt sie wieder zurück, obwohl das eigentlich nicht nötig ist, weil Linux die zusätzlichen carriage returns ignoriert.
Es wäre eine einfache Angelegenheit, diese beiden Dateien mit zwei Alias, z. B. L2d & d2l, zu versehen und sie in ein Script zu integrieren.
Für dieses ist die Syntax sehr einfach:
sed {Optionen} {Befehl} {Datei}
optionen
Für die Version von GNU sed, die wohl die meisten Linux Nutzer installiert haben, sind die gebräuchlichsten Optionen:
-e wird benötigt, wenn auf der Kommandozeile Befehle spezifiziert werden und der Anwendung mitgeteilt werden soll, dass das was folgt als Befehl anzusehen ist, der in der gegenwärtigen Zeile anzuwenden ist. Die Option kann auf der Kommandozeile wiederholt werden und so können mehrfache Befehle auf die Eingabedaten wirken.
-n Still Modus, gibt nicht automatisch Zeilen an stdout aus.
-f script Der Inhalt des benannten Scripts wird zum auszuführenden Befehl hinzugefügt.
-r Nutzung des erweiterten Satzes regulärer Ausdrücke (wie egrep).
--posix Abschalten von gnu Erweiterungen. Dies erlaubt es, die Scripte in Systeme mit der Standard UNIX Version von sed zu Portieren.
--help beinhaltet alle Optionen der Version, die Sie benutzen.
Befehle
Hier wird definiert, was mit den Daten geschehen soll, die vom Datenstrom geliefert werden. Wir werden die Wichtigsten in diesem Beitrag kennenlernen.
Datei
Hierbei handelt es sich um den Input Datenstrom. Wenn der Dateiname über die Kommandozeile geliefert wird, wird er als stdin angesehen. Das heißt, dass sed command file und sed command < file dasselbe bedeuten. Die Eingabe kann dem Befehl auch über eine Pipe übergeben werden, z. B. cat file | sed command oder ls -l | sed command.
Wenn Sie damit Erfahrung sammeln wollen, suchen Sie sich eine Datei aus und spielen Sie damit. Ich habe hier mit ls -A|LGgh /boot >sed-demo eine kurze Liste der Dateien aus meinem /boot Verzeichnis angelegt und diese in einer Datei mit Namen sed-demo gespeichert. Das sieht dann so aus:
total 31M -rw-rw-r-- 1 440 2010-04-02 10:59 boot.backup.sda -rw-r--r-- 1 111K 2010-04-03 15:11 config -rw-r--r-- 1 108K 2010-03-16 15:11 config-2.6.32.10-pclos2.pae -rw-r--r-- 1 111K 2010-04-03 15:11 config-2.6.33.2-pclos1.pae -rwxr-xr-x 1 579K 2010-04-02 10:59 gfxmenu* drwxr-xr-x 2 4.0K 2010-04-05 04:11 grub/ -rw------- 1 6.4M 2010-04-02 11:35 initrd-2.6.32.10-pclos2.pae.img -rw------- 1 6.4M 2010-04-04 08:56 initrd-2.6.33.2-pclos1.pae.img -rw------- 1 6.4M 2010-04-04 08:56 initrd.img -rw-r--r-- 1 1.5K 2010-04-10 14:04 kernel.h -rw-r--r-- 1 1.5K 2010-04-02 11:59 kernel.h-2.6.32.10-pclos2.pae -rw-r--r-- 1 1.5K 2010-04-10 14:04 kernel.h-2.6.33.2-pclos1.pae -rw-r--r-- 1 249K 2006-11-05 23:23 message-graphic -rw-r--r-- 1 1.4M 2010-04-03 15:11 System.map -rw-r--r-- 1 1.4M 2010-03-16 15:11 System.map-2.6.32.10-pclos2.pae -rw-r--r-- 1 1.4M 2010-04-03 15:11 System.map-2.6.33.2-pclos1.pae -rw-rw-r-- 1 256 2010-04-02 10:59 uk-latin1.klt -rw-r--r-- 1 2.0M 2010-04-03 15:11 vmlinuz -rw-r--r-- 1 2.0M 2010-03-16 15:11 vmlinuz-2.6.32.10-pclos2.pae -rw-r--r-- 1 2.0M 2010-04-03 15:11 vmlinuz-2.6.33.2-pclos1.pae
Diese Datei enthält eine Mischung aus Zeilen unterschiedlicher Länge und aus unterschiedlich angelegten Feldern. Ohne den sed Befehl wäre die Auswahl von Daten, die spezifische Merkmale aufweisen und ihre Umformatierung nach meinen Bedürfnissen, eine äußerst schwierige Angelegenheit.
Am Datensatz möchte ich folgende Änderungen vornehmen:
- Entfernen des Zählers für die Gesamtanzahl
- Nur echte Dateien erfassen und keine Links, Verzeichnisse usw.
- Entfernen der Erlaubnisfelder
- Entfernen der Abzählung von Links
- Ausschließliche Erfassung von Zeilen, die Dateien mit 1 MB Größe oder mehr enthalten
- Austausch von 'M' in 'MegaBytes'
- Ersetzen des Datumsformats von year-month-day in day/month/year
- Entfernen des Zeitfeldes
- Ausgabe von Dateigröße und Dateiname – in dieser Reihenfolge.
Dies sieht ja nun nach einer Menge Arbeit aus, aber Dank sed kann ich alles mit einem Befehl erledigen.
Um die Zeile 'total 31M' loszuwerden und um nur Zeilen mit Einzelheiten zu belassen, könnte ich folgenden Befehl verwenden:
sed -e '/total/d' sed-demo
Hier sehen Sie den Anfang der Ausgabe dieses Befehls:

Die Zeile am Anfang der Liste mit dem Begriff total ist von der Ausgabe verschwunden.
Was habe ich jetzt hier gemacht? Ich habe den sed Befehl mit der -e Option verwendet. Dies veranlasst den sed Befehl, das nächste Argument der Kommandozeile '/total/d' als Befehl zu betrachten, der auf die Eingabedatei sed-demo anzuwenden ist.
sed hat Folgendes gemacht: die gesamte sed-demo Datei wurde Zeile für Zeile in einen Speicherbereich eingelesen, der pattern Bereich genannt, sie wurde und Zeile für Zeile auf Übereinstimmung mit dem regulären Ausdruck total, der von Slashzeichen eingerahmt ist, geprüft. Jedes Mal, wenn eine Übereinstimmung gefunden wird, führt sed den d Befehl aus, der die jeweilige Zeile aus dem pattern Bereich entfernt. Das Ergebnis ist, dass sed von der Analyse dieser Zeile keine Ausgabe macht. Zeilen, die keine Übereinstimmung mit dem Muster ergeben, bleiben unberücksichtigt und durchlaufen den Befehl zu stdout, was in diesem Fall das Terminal ist, da die Ausgabe nicht irgendwo anders hin umgeleitet wurde.
Es ist nicht schwer, den Gebrauch von sed in diesem einfachen Beispiel zu verstehen. Der Schlüsselbegriff ist regulärer Ausdruck ('regular expression'). Um den Befehl effizient benutzen zu können, muss der Begriff 'regular expression' gut verstanden worden sein.
Die Grundlagen von regular expressions haben wir schon beim grep Befehl behandelt, eine kleine Erinnerung ist ganz gut.
Eine regular expression ist eine Abfolge wörtlicher Zeichen und Meta Zeichen. Wörtliche Zeichen werden genauso behandelt, wie sie eingegeben wurden und unterscheiden zwischen Groß- und Kleinschreibung. Meta Zeichen besitzen in regulären Ausdrücken eine spezielle Bedeutung. Sie müssen zur Darstellung des Suchmusters des regulären Ausdrucks erweitert werden. Die wichtigsten Meta Zeichen sind:
- .
- Der Punkt steht für Übereinstimmung mit jedem einzelnen Zeichen.
- *
- Der Stern steht für kein oder mehrfaches Vorkommen des vorstehenden Zeichens. Dies ist nicht dasselbe wie das wild-card Zeichen der Shell.
- ^
- Das Einschaltungszeichen ist knifflig und hat 2 Bedeutungen. Außerhalb eckiger Klammern steht es für ein Zeichen nur dann, wenn dieses am Anfang einer Zeile steht. Es wird dann Sprungmarke genannt. Steht es hingegen als erstes Zeichen innerhalb eines Klammerpaares, so negiert es Übereinstimmung d. h. "stehe für alles, außer für das, was folgt".
- $
- Eine weitere Sprungmarke. Diesmal bedeutet sie, Übereinstimmung am Zeilenende.
- \< \>
- Weitere Sprungmarken, stehen für ein Muster am Anfang \< oder Ende \> eines Wortes.
- \
- Das Zitierzeichen oder Escapezeichen wird verwendet um die spezielle Bedeutung des direkt folgenden Zeichens aufzuheben.
- [ ]
- Eckige Klammern enthalten Gruppen, Bereiche oder Klassen von Zeichen. Eine Gruppe kann auch ein einzelner Buchstabe sein.
- \{n\}
- Steht für n Übereinstimmungen mit dem vorstehenden Zeichen oder regulärem Ausdruck. Beachten Sie, dass n für eine einzelne Zahl \{2\}, einen Bereich \{2,4\} oder eine kleinste Anzahl \{2,\} (mindestens 2 Übereinstimmungen) stehen kann.
- \( \)
- Aller Text zwischen \( und \) wird in einem besonderen temporären Puffer gespeichert. Auf diese Weise können bis zu 9 Sequenzen gespeichert und mit den Befehlen \1 bis \9 eingefügt werden.
Im vorangegangenen Beispiel enthielt der von uns benutzte reguläre Ausdruck total nur wörtliche Zeichen. Häufiger jedoch werden wir reguläre Ausdrücke aus wörtlichen Zeichen, meta Zeichen, und aus Zeichenklassen wie [:digit:] oder [:space:] bilden. Durch die Benutzung von meta Zeichen in regulären Ausdrücken können Sie sehr schnell die Übereinstimmung mit komplizierten oder unbekannten Mustern feststellen. Einige Beispiele:
sed -e '/^#'d' .bashrc entfernt aus Ihrer .bashrc Datei jeden Kommentar, weil Kommentare mit einem # beginnen.
sed -e '/^$/d' .bashrc entfernt alle leeren Zeilen, indem Übereinstimmung dafür gesucht wird, dass zwischen Zeilenanfang und Zeilenende nichts steht.
Es ist recht sicher, diese (Befehle) auszuprobieren, da die Ursprungsdatei nicht verändert wird. Nur die Ausgabe ans Terminal wird geändert.
In meiner Testdatei habe ich ein Verzeichnis /grub. Es ist am Zeilenanfang durch den Buchstaben d gekennzeichnet. Um die Zeile zu entfernen, können wir den Löschbefehl von sed mit einem regulären Ausdruck, der nur mit dieser Zeile übereinstimmt, benutzen.
sed -e '/^d/d' sed-demo findet alle Zeilenanfänge, das ist das ^, mit d und führt den Löschbefehl aus. Der Befehl steht in einfachen Anführungszeichen, um Shellerweiterungen von meta Zeichen zu verhindern. Erinnern Sie sich daran, dass die einfachen Anführungszeichen, auch starke Anführungszeichen genannt, den Inhalt dazwischen vor der Shellerweiterung schützen. Hier wäre das nicht von Bedeutung gewesen, es ist aber eine gute Angewohnheit, sie anzuwenden.
Um Verzeichnisse zu erhalten, und alle anderen Zeilen zu entfernen, müssen wir den umgekehrten Effekt des Befehls benutzen. Das geht so:
sed -n -e '/^d/p' sed-demo
Das -n schaltet automatisches echo des Zeichenmusters an das Terminal ab, und der p Befehl gibt bei Musterübereinstimmung den gegenwärtigen Inhalt des Zeichenmusters an stdout aus, was in diesem Fall das Terminal ist, da nicht umgeleitet.
Alternativ könnten wir nach Zeilen Ausschau halten, die mit einem Hyphen beginnen. Das würde auch alles ausschließen, was keine reguläre Datei ist.
sed -n -e '/^-/p' sed-demo
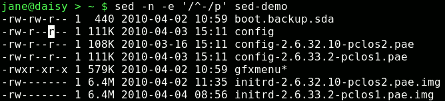
Die Zeile für das Verzeichnis ist verschwunden, aber auch die Zeile mit total ist weg, da sie nicht mit einem Hyphen beginnt. In diesem Fall ist es hilfreich, aber wir müssen außerordentlich vorsichtig bei dem sein, was wir ein- oder ausschließen wollen. Auf dieselbe Weise können wir alle Zeilen entfernen, die kein großes M, gefolgt von einem Leerzeichen enthalten. Damit verbleiben nur Dateien mit einer Größe von 1 MB oder mehr. Ohne das Leerzeichen würde die total Zeile, die auch ein großes M, aber kein folgendes Leerzeichen enthält, miteinbezogen.
sed -n -e '/M /p' sed-demo

Im ersten Beispiel habe ich die Übereinstimmung mit dem Muster total benutzt, um die erste Zeile zu entfernen, es wäre aber einfacher gewesen, eine Adresse anzugeben.
sed -e '1d' sed-demoDie 1 ist die Zeilennummer, die ich entfernen will. Adressen können auch Bereiche sein. sed -e '8,20d' entfernt die Zeilen 8 bis 20 von der Ausgabe.

Beachten Sie, dass die total Zeile und die Verzeichniszeile weiterhin ausgegeben werden, weil die Originaldaten nicht verändert wurden.
In diesem speziellen Fall wusste ich, dass die Adresse 1 war, aber normalerweise hätte ich sie suchen müssen. Das macht man, indem man einen, in Slashes gesetzten regulären Ausdruck spezifiziert. Im ersten Beispiel war die Adresse der zu entfernenden Zeile durch die Übereinstimmung mit dem regulären Ausdruck /total/ gegeben.
Substitution
Jetzt, da uns die Mittel zur Verfügung stehen, nur die Zeilen auszusuchen, die wir in unserem endgültigen Datensatz haben wollen, müssen wir einige dieser Daten ändern. Der wahrscheinlich am Meisten benutzte Befehl von sed ist s. Damit wird ein regulärer Ausdruck durch einen anderen ersetzt. Das Format hierfür ist:
sed -e 's/old/new/' {Datei}
Also würde der Befehl
sed -e 's/M/ MegaBytes/' sed-demo
in meiner Testdatei alle großen MS (und nicht das voranstehende Leerzeichen) in 'MegaBytes' umwandeln. Beachten Sie, dass sed standardmäßig nur das erste Auftreten der Übereinstimmung des Musters in einer Zeile überprüft. Wenn Sie alle Übereinstimmungen finden wollen, und das wollen Sie vielleicht öfters, dann müssen Sie den g -global Befehl anfügen:
sed -n -e 's/r/R/p' sed-demo ersetzt nur das erste r durch R.
sed -n -e 's/r/R/gp' sed-demo ersetzt jede Übereinstimmung.
Wenn wir zwei Befehle kombinieren, können wir eine Substitution durchführen und nur die Zeilen ausgeben, die wir behalten wollen.
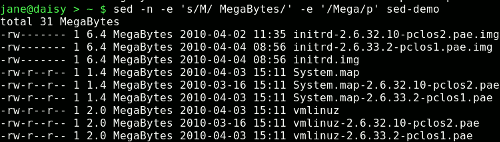
sed -n -e 's/M/ MegaBytes/' -e '/Mega/p' sed-demo
Mit dem substitute Befehl kann man auch einen Teil einer Zeile leicht entfernen. Zur Entfernung des Zeitfeldes könnten wir die Übereinstimmung mit 2 Zeichen, gefolgt von einer Spalte, benutzen und es durch etwas ersetzen wie:
sed -e 's/..:..//' sed-demo
Um die Rechte(Anzeige), die Angabe der Anzahl der Links und das führende Leerzeichen am Anfang der Zeile zu entfernen, können wir nach Übereinstimmung mit einem Hyphen, gefolgt von genau 12 Zeichen suchen, indem wir die Metazeichen Punkt, \{ & \} benutzen.
sed -e 's/-.\{12\}//' sed-demo
Der Punkt bedeutet Übereinstimmung mit jedem Zeichen und die Zahl innerhalb der geschwungenen Klammer teilt dem Befehl mit, wie viele Übereinstimmungen gesucht werden. Das heißt: Finde genau 12 Zeichen.
Wenn wir reguläre Ausdrücke zusammen mit Metazeichen benutzen, müssen wir uns darüber im Klaren sein, dass sie raffgierig sind. Sie suchen immer Übereinstimmung mit der längstmöglichen Zeichenkette.
Wenn Sie versuchen, Rechte mit einem Befehl wie:
sed -n -e 's/-.*-//p' sed-demo
zu entfernen, indem Sie nach einem Hyphen suchen, dann werden Sie enttäuscht feststellen, dass bei Übereinstimmung mit Zeichenketten wie
-rw-r--r-- 1 111K 2010-04-03 15:11 config-2.6.33.2-
nur
pclos1.pae ausgegeben wird.
Wenn wir alle diese Dinge zusammenfassen, ergibt sich eine ziemlich lange Kommandozeile. Daher habe ich das Zeilenverlängerungszeichen für die Shell, den Backslash, verwendet, um es lesbarer zu machen. Aber denken Sie daran, soweit es die Shell betrifft, ist alles nur eine Zeile.

Die Geschicklichkeit bei der Benutzung von sed ist zu erkennen, womit Übereinstimmung hergestellt werden soll und einen regulären Ausdruck aufzubauen, der mit diesem Teil der Zeile und nur mit diesem übereinstimmt. Dafür muss man Verständnis und Erfahrung mit regulären Ausdrücken erwerben. Übereinstimmung mit einem Dateinamen herzustellen ist recht kitzlig, da es kein einfaches Standardformat zu geben scheint. Also ist es am Einfachsten Übereinstimmung mit allem Anderen zu finden.
sed -e 's/-.\{34\}//' sed-demo
Hier der Beginn der Ausgabe:

Nein, ich habe nicht alle 34 Zeichen gezählt. Ich habe geschätzt, es ausprobiert und angepasst. Diese Methode des trial and error ist beim Erstellen regulärer Ausdrücke recht verbreitet, wird aber nicht von Allen geschätzt.
Sie haben vielleicht bemerkt, dass die total Zeile in der Ausgabe erscheint. Das kommt daher, dass sie nicht mit einem Hyphen beginnt und wir sie noch nicht entfernt haben. Die Reihenfolge der Ausführung Ihrer Befehle kann große Auswirkungen auf das Ausgaberesultat aufweisen.
sed -e 's/[0-9]\{4\}-[0-9][0-9]-[0-9][0-9]//' sed-demo
erzeugt Übereinstimmung mit Datenteil der Zeile und entfernt ihn. Das funktioniert so.
Der erste Slash startet den Suchausdruck.
- [0-9]\{4\}
- erzeugt Übereinstimmung mit genau 4 Ziffern
- -
- passt auf ein wörtliches Hyphen
- [0-9][0-9]
- Übereinstimmung mit 2 Ziffern
- -
- passt auf ein wörtliches Hyphen
- [0-9][0-9]
- Übereinstimmung mit 2 Ziffern
- \4
- zunächst \4, den Tag
- \/
- gefolgt von einem forward slash, der escaped werden muss, da wir ansonsten den Substitutionsbefehl beenden würden
- \3
- gefolgt von \3 – dem Monat
- \/
- gefolgt von einem Slash
- \2
- gefolgt von \2 – dem Jahr
- \1
- gefolgt von einem Leerzeichen und \1 - der Dateigröße
- \5/p'
- und schließlich ein Leerzeichen und \5 der Dateiname, der Slash zur Beendigung des Substitutionsbefehls und der p Befehl für die Ausgabe der substituierten Daten.
- sed-demo
- Tist der Dateinamen ist der Dateiname, den wir sed zur Bearbeitung übergeben haben.
Der zweite Slash beendet den Suchausdruck. Wenn eine Übereinstimmung gefunden wird, wird sie durch das ersetzt, was zwischen dem 2ten und dem 3ten Slash steht, in diesem Fall durch nichts. In der Testdatei findet sich zum Beispiel in der zweiten Zeile eine Übereinstimmung, 2010-04-02. Sie wird entfernt.
Jetzt stehen uns fast alle Methoden zur Verfügung, um die Aufgabe zu bewältigen, aber der Befehl gestaltet sich recht plump. Wir könnten ein Script mit all den Befehlen schreiben, aber es gibt noch einen anderen Weg, die meta Zeichen \( und \) zu nutzen. Alles, was mit dem regulären Ausdruck, der zwischen diesem Paar steht, übereinstimmt wird gespeichert und kann für spätere Einbeziehung wieder aufgerufen werden. Übereinstimmung mit dem ersten Paar wird mit \1 aufgerufen, mit dem 2ten Paar mit \2 und so weiter bis \9.
Hier ist nun der endgültige Befehl. Er schaltet das automatische Zeilenecho aus, überprüft die gesamten gespeicherten Zeilenteile auf Übereinstimmung und gibt dann einige dieser gespeicherten Teile in der geforderten Reihenfolge aus.
sed -n -e 's/M/ MegaBytes/' -e 's/-.\{12\}\(.\.. MegaBytes\) \([0-9]\{4\}\)-\([0-9][0-9]\)-\([0-9][0-9]\) ..:.. \(.*$\)/\4\/\3\/\2 \1 \5/p' sed-demo
Eine andere Art, diesen Befehl ohne die -e Option zu schreiben ist es, die Befehle durch ein Semikolon zu trennen.
sed -n -e 's/M/ MegaBytes/';s/-.\{12\}\(.\.. MegaBytes\) \([0-9]\{4\}\)-\([0-9][0-9]\)-\([0-9][0-9]\) ..:.. \(.*$\)/\4\/\3\/\2 \1 \5/p' sed-demo
Ich selbst kann letzterem nicht so leicht folgen, aber es ist Ihre Wahl.

Man kann dem einfacher nachgehen, wenn man es aufteilt. Zur Erinnerung hier nochmals eine typische Zeile für die Eingabedatei.
-rw-rw-r-- 1 440 2010-04-02 10:59 boot.backup.sda
sed -n -e 's/M/ MegaBytes/'
Der erste Ausdruck erzeugt die Substitution von 'M' durch ein Leerzeichen, gefolgt von dem Wort MegaBytes.
-e 's/-.\{12\}
Der zweite Ausdruck, ebenfalls einen Substitution, ersetzt ein Hyphen, gefolgt von genau 12 Zeichen.
\(.\.. MegaBytes\)
Auf ein Zeichen folgt ein Punkt (der zur Aufrechterhaltung seiner wörtlichen Bedeutung escaped werden muss), dann ein weiteres Zeichen, ein Leerzeichen und das Wort MegaBytes. Alle übereinstimmenden Daten werden unter \1 gespeichert. Dies ist die Größe (der Datei).
\([0-9]\{4\}\)
gefolgt von genau 4 Zeichen, die in \2 gespeichert werden entsprechen dem Jahr.
-\([0-9][0-9]\)
gefolgt von 2 Zeichen wird in \3 als Monat gespeichert.
-\([0-9][0-9]\)
gefolgt von 2 Zeichen wird in \4 als Tag gespeichert.
..:..
gefolgt von einem Leerzeichen, zwei Zeichen, einer Spalte, zwei weiteren Zeichen und einem Leerzeichen entsprechen der Zeit, aber die benutzen wir nicht, und dies wird nicht gespeichert.
\(.*$\)/
gefolgt von einer beliebigen Anzahl von Zeichen mit dem $ Zeichen für das Zeilenende. Dabei handelt es sich um den Dateinamen, der in \5 gespeichert wird. Dieser beendet den Suchabschnitt der Substitution.
Hiermit werden wir die Daten für die Übereinstimmung gefunden wurde ersetzen:
Easy peasy :)
Im wirklichen Leben ist so ein Befehl natürlich viel zu lang um über die Kommandozeile eingegeben zu werden. Normalerweise würde so eine komplexe Operation in eine Datei geschrieben und von sed mit der -f Option angesprochen.
Haben wir unsere Befehle in eine Datei geschrieben, so können wir ganz einfach solange testen und anpassen, bis wir das gewünschte Resultat erhalten. Wir können auch mehrfache Befehle, die auf die gleiche Adresse oder auf die gleiche Zeile wirken sollen, in Gruppen anlegen, indem wir sie in geschwungene Klammern setzen. Im vorausgehenden Beispiel haben wir M durch Megabytes ersetzt, aber in Wirklichkeit hätten wir wohl M durch MB und K durch KB ersetzen wollen. So können wir eine sed-Datei (nennen Sie sie, wie Sie wollen) mit folgendem Text erzeugen:
{
s/K/KB/
s/M/MB/
p
}
und dann ausführen:
sed -n -f mysed-file sed-demo
Da wir vor der ersten geschweiften Klammer keine Adresse angegeben haben, werden alle Zeilen abgearbeitet, beide Substitutionen an jeder Zeile vorgenommen und dann am Terminal ausgegeben.
Versuchen wir noch eine andere Testdatei. Hier ist eine sehr einfache HTML Datei die sich für eine Neukonfiguration durch sed anbietet. Ich habe sie 2010.html genannt. Sorgen Sie sich nicht, wenn Sie html Code nicht verstehen. Das einzige, was Sie wissen müssen ist, dass die Dinge, die zwischen <> stehen das Format und das Aussehen der Webseite beeinflussen. <p> beginnt einen Abschnitt und </p> beendet ihn. Diese werden als Marken (tags) bezeichnet.
<body> <h1>PCLinuxOS 2010 Release</h1> <p>Texstar recently anounced the release of the 2010 version of this popular distribution.</p> <h2>Now available in the following versions</h2> <p><li><em>KDE4</em> The base distribution</li></p> <p><li><em>Minime</em> Minimal KDE4 installation</li></p> <p><li><em>Gnome</em> Full installation of Gnome</li></p> <p><li><em>ZenMini</em> Minimal Gnome distribution</li></p> <p><li><em>LXDE</em> A lightweight desktop</li></p> <p><li><em>Phoenix</em> The XFCE desktop</li></p> <p><li><em>Enlightenment</em> The beautiful e17 desktop</li></p> <p><li><em>Openbox</em> Suitable for older hardware</li></p> </body>
Im Firefox sieht das so aus:

Der hervorgehobene oder schräggestellte (italic) Text wird durch die Marken <em> und </em> ein- und ausgeschaltet. Wenn man das in Fettdruck umschalten will muss man em durch b ersetzen.
Will man diese Änderung nur für auf KDE beruhenden Distributionen durchführen, müssen wir eine Start und eine Endadresse bereitstellen und die Ausgabe in eine andere Datei schreiben.
sed -e '/KDE4/,/Minime/s/em>/b>/g' 2010.html >2010b.html
Die Startadresse ist die erste Übereinstimmung mit KDE4 und Endadresse die erste Übereinstimmung mit Minime.

Voila! Alles ausgeführt.
sed verfügt über drei weitere Befehle, die nicht oft angewendet werden. Wegen ihrer ungewöhnlichen Zweizeilensyntax verwendet man sie am Besten mit Hilfe einer Datei. Es sind a – append, i – insert und c – change.
Unsere neue html Testdatei hat eine Unterüberschrift (Kopfzeile), die durch das <h2></h2> Paar identifiziert werden. Normalerweise wären dort viele solcher Kopfzeilen und wahrscheinlich auch ein Verzeichnis mit vielen html Dateien. In so einem Fall kann das Gesamterscheinungsbild einer Webseite vollständig durch ein kleines sed Script verändert werden. Unsere kleine Testdatei reicht aus, um die Wirkung dieser Befehle zu demonstrieren.
Wenn ich mit folgendem Text
/<h2>/{
i\
_________________________________________________
a\
_________________________________________________
}
eine Datei erstelle, diese sed-file nenne und dann den Befehl:
sed -f sed-file 2010.html > 2010new.html
ausführen lasse, dann dann wird vor jeder Zeile mit der <h2> Marke eine Reihe Unterstriche eingefügt und danach angehängt (das <h2> tag ist die Adresse auf die die Befehlsgruppe zwischen den geschweiften Klammern angewendet wird).
Der c Befehl funktioniert auf dieselbe Art und Weise und tauscht in jeder übereinstimmenden Zeile(n) den bereitgestellten Text aus. Wenn die angegebene Adresse einen Zeilenbereich überdeckt, dann wird der gesamte Textblock durch eine einzige Kopie des neuen Textes ersetzt.
Zusätzlich zu den Befehlen, die ich hier vorgestellt habe, verfügt sed noch über viele mehr, deren Behandlung einen Einführungstext überlasten würde. Da gibt es Befehle zur Flusskontrolle, wie b -branch, die es einem Script unter bestimmten Bedingungen ermöglichen, eine Schleife auszuführen. Es gibt auch Marken, die wir anspringen können, um bestimmte Operationen in Abhängigkeit von der Ausgabe vorheriger ausführen zu lassen. Letzteres wird üblicherweise durch den t– test Befehl bestimmt.
Es gibt auch eine Befehlsgruppe, die dazu dient, Veränderungen in einem Speicherbereich, der Haltebereich hold space genannt wird auszuführen. sed liest Eingabezeilen in den als pattern space bezeichneten Speicherbereich ein und einige oder alle dieser Daten können zeitweise in den hold space kopiert werden, ähnlich einem Notizblock. sed kann den Inhalt des hold space nicht bearbeiten. Es kann lediglich etwas hinzufügen, aus ihm lesen, oder mit einem anderen austauschen. Die Befehle dazu sind: g, G, h,H, x. Sie werden mit get (vom pattern space), hold (in pattern space) und exchange (swap) bezeichnet. Mit den Großbuchstaben werden die Daten angehängt, Kleinbuchstaben bewirken das Überschreiben der Daten.
Der letzte Befehl, den ich hier erwähnen möchte ist y. Auf eine nicht sehr intuitive Art bedeutet er: ersetze die Zeichen eines Strings durch die Zeichen eines anderen Strings unter Beibehaltung der Zeichenposition. Das n-te Teichen des ersten Strings wird durch das n-te Zeichen des zweiten Strings ersetzt. Dies wird, wie üblich am einfachsten durch ein Beispiel deutlich.
Hier wird eine Zeile auf Kleinbuchstaben umgestellt, um Missverständnisse bei der Interpretation eines Scripts durch die Shell zu vermeiden.
sed 'y/ABCDEFGHIJKLMNOPQRSTUVWXYZ/abcdefghijklmnopqrstuvwxyz/' myscript.sh