Einführung: Schnittstelle Kommandozeile
Teil 6
von Peter Kelly (critter)
Übersetzt von Nil
Korrektur gelesen von Angel02_de
Globbing
Was ist denn das? Nun, das ist ein ungewöhnlicher Begriff. Er geht auf die Art und Weise zurück, wie Kommandointerpreter der frühen Unix-Zeit die Dinge gehandelt hatten.
Bei der Angabe von Dateinamen anerkennt die Shell gewisse Zeichen als Wildcards. Diese können zur Kennzeichnung unbekannter oder mehrfach vorkommender Zeichen verwendet werden. Einige dieser Zeichen haben wir schon in Kapitel 3 kennengelernt nämlich '*' und '?'. Diese sind am gebräuchlichsten, aber es können auch Gruppen und Klassen von Zeichen verwendet werden. Wenn die Shell in einem Dateinamen auf eine dieser Wildcards trifft, wird diese an dieser Stelle durch den Inhalt dessen ersetzt, wofür die Wildcard steht. Je nachdem, wie pedantisch oder spitzfindig man ist, bezeichnet man diesen Vorgang als „Dateinamenerweiterung“, „Vervollständigung des Pfadnamens“, „Shell-Erweiterung“ oder „Globbing“.
Dabei gilt Folgendes:
- *
- füge an dieser Stelle irgendein oder mehrere Zeichen ein, die zutreffend sind
- ?
- füge an dieser Stelle genau das zutreffende Zeichen ein.
Einzelne Zeichen können in Gruppen zusammengefasst werden:
- [a,f]
- trifft entweder auf a oder f zu
- [a-m,w-z]
- trifft nur auf Zeichen aus den Bereichen a-m oder w-z zu
- [a-z,0-9]
- trifft auf alle Kleinbuchstaben und alle Ziffern zu
- [!a-c]
- trifft auf jedes Zeichen zu außer a-c
- [^a-c]
- wie oben

Die Verwendung vordefinierter Klassen stellt einen anderen Weg dar, Zeichengruppen zu kennzeichnen. Das sind Zeichengruppen, die im POSIX Standard definiert sind. Die Syntax hierfür ist [:class:].
Zu den definierten Klassen zählen:
- [:alnum:]
- jedes alphanumerische Zeichen [0-9, a-z, A-Z]
- [:alpha:]
- Zeichen des Alphabets [a-z, A-Z]
- [:blank:]
- nicht sichtbare Zeichen wie Leerstellen und Tabulatoren (auch als 'whitespace' bezeichnet)
- [:digit:]
- numerische Zeichen [0-9]
- [:punct:]
- Punktzeichen
- [:lower:]
- Kleinbuchstaben [a-z]
- [:upper:]
- Großbuchstaben [A-Z]
- [:xdigit:]
- jedes Zeichen, das zur Bildung einer Hexadezimalzahl herangezogen werden kann [0-9, a-f, A-F]
ls -d [[:upper:]]* findet demnach alle Dateien und Verzeichnisse, die mit einem Großbuchstaben anfangen.

Beachten Sie, dass hier 2 Paare Klammern nötig sind, ein Paar um Beginn und Ende des Bereichs zu kennzeichnen, das zweite Paar enthält die Klassenbezeichnung.
All diese Verfahren können kombiniert werden, um genau den Satz von Dateien zu finden, den Sie suchen. Diese Art der Dateinamenerweiterung kann die Anzahl der Dateien, die Sie mit Ihren Befehlen ansprechen, vergrößern oder verkleinern.
In diesen Erweiterungen ist das Punktzeichen '.' nicht enthalten. Geben Sie in Ihrem Heimatverzeichnis ls -al ein. Sie werden sehen, dass es eine ganze Menge Dateien gibt, deren Namen mit diesem Zeichen beginnt. Das sind sogenannte 'versteckte' Dateien. Um sie anzeigen zu können, verwenden wir die -a Option im ls Befehl. In jedem Verzeichnis sind die ersten beiden Dateinamen die Namen des Verzeichnisses '.' und '..'. Diese beziehen sich direkt auf das gegebene Verzeichnis '.' und dessen übergeordnetes Verzeichnis '..'.Wozu braucht man das eigentlich? Ein Grund ist, dass es dadurch möglich ist, ein Verzeichnis zu erreichen, ohne im Einzelnen dessen Namen angeben zu müssen.
- cd ..
- bringt Sie eine (Verzeichnis)ebene höher
- cd ../..
- bringt Sie 2 Ebenen höher und so weiter.
Wenn Sie ein Script ausführen wollen, das Sie geschrieben haben, muss es in Ihrem PATH ((Verzeichnispfad; eine Liste von Verzeichnissen, die nach ausführbaren Dateien durchsucht werden) enthalten sein, andernfalls müssen Sie die vollständige absolute Adresse der Datei angeben. Es ist einfacher ./myscript {dieses Verzeichnis/myscript} einzugeben als /home/jane/myscripts/myscript.
Es ist aus Sicherheitsgründen jedoch nicht angeraten ihr Heimatverzeichnis in Ihren Pfad PATHaufzunehmen.
Wie kann man nun versteckte Dateien in unsere Liste von Dateien, mit denen wir arbeiten wollen aufnehmen, wenn das Punktzeichen nicht Teil der Dateierweiterungen ist und wir gleichzeitig die zwei Verzeichnisabkürzungen '.' und '..' vermeiden wollen?
Nehmen wir dazu an, dass wir alle Dateien eines Verzeichnisses mit der Dateierweiterung '.bak' umbenennen wollen, aber einige dieser Dateien versteckte 'Punkt'dateien sind. Wenn wir versuchen alle Dateien einschließlich jener umzubenennen, deren Name mit einem Punkt beginnt, schließen wir '.' und '..' mit ein, was wir nicht wollten (es wird eine Fehlermeldung geben).
Wir könnten zwei Listen machen, eine mit normalen Dateien und eine, deren Dateinamen mit einem Punkt beginnen und bei letzterer die nicht gewünschte Punktdateien ausfiltern, oder wir könnten auch die Shell dazu bringen, diese Arbeit für uns zu erledigen. Die Bash Shell verfügt über eine Menge von Optionen. Sie wird standardmäßig von der von Ihnen verwendeten Distribution gestartet und ist beim täglichen Gebrauch äußerst hilfreich.
Um eine Liste dieser verfügbaren Optionen zu erhalten geben Sie shopt -sein.Der shopt Befehl zeigt den Status der verfügbaren shell optionen an. shopt -u zeigt die nicht gesetzten Optionen an.
Die, die wir hier suchen, heißt dotglob.
Wenn diese Option gesetzt ist, werden die Punkte, die eine versteckte Datei kennzeichnen, als Erweiterung erkannt, die zwei Verzeichniseinträge aber werden ignoriert. Der Befehl shopt -s dotglob schaltet die Option ein und shopt -u dotglob wieder aus. Vergessen Sie nicht dies auszuführen, ansonsten finden Sie sich in unbekanntem Gelände wieder.
Um alle Dateien umbenennen zu können, brauchen wir eine Schleife. Ich werde dies näher erklären, wenn wir zu den Shell Scripten kommen, - die wahre Stärke der Shell. Für den Augenblick folgen Sie einfach den nachstehenden Vorgaben.
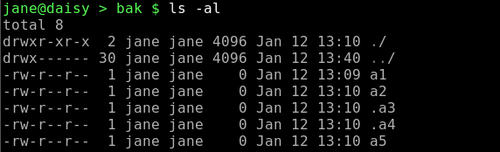
ls -al zeigt zwei unerwünschte Abkürzungen auf Verzeichnisse an und 5 Dateien, davon 2 versteckte.
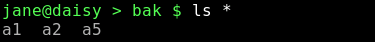
Der '*' erweitert nicht für eine Anzeige der versteckten Dateien oder der Verzeichnisabkürzungen.
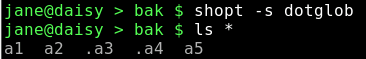
Wenn wir die dotglob Option der Shell einschalten, erweitert die Wildcard '*' die Anzeige auf alle Dateien, die Verzeichnisabkürzungen ausgenommen.
Jetzt können wir unsere Schleife laufen lassen. Eine Überprüfung zeigt, dass alle Dateien umbenannt wurden.
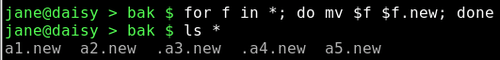
Schalten wir die Option aus, so fallen wir in den Standardmodus zurück, bei dem Punktdateien nicht erweitert werden.

Die Erweiterungen der Shell sind nicht auf Dateinamen begrenzt. Es gibt 6 Erweiterungsebenen, die von der Shell erkannt werden. In alphabetischer Reihenfolge sind dies:
- Arithmetische Erweiterungen
- Klammererweiterungen
- Dateinamenerweiterungen
- Zeitverlaufserweiterungen
- Erweiterungen der Shell Parameter
- Tilde Erweiterungen
Wenn Sie sich nicht mindestens dieser Erweiterungen bewusst sind, sollten Sie sich nicht wundern, wenn Sie bei ihrer Anwendung merkwürdige Ergebnisse erzielen.
Arithmetische Erweiterung. Die Shell führt in begrenztem Rahmen Arithmetik ganzer Zahlen durch. Je nach Zustand der Shell haben die verschiedenen Operatoren eine unterschiedliche Bedeutung. Diese (Operatoren) sind:
- +
- Addition
- -
- Subtraktion
- *
- Multiplikation
- /
- Division
- **
- Exponent
(Normalerweise '^'. Dies wird aber in den Shell Erweiterungen als Negation verwendet) - %
- Modulo (Rest)
Die Syntax ist $((Ausdruck)). Beachten Sie wieder das Klammerpaar. Ausdrücke können im ersten Klammerpaar verschachtelt werden, der Standardoperator geht voraus. Innerhalb des Ausdrucks haben whitespace Zeichen keine Bedeutung.
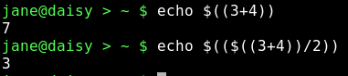
3 + 4 = 7
7 / 2 = 3 nur ganze Zahlen
Erweiterung TildeDiese lassen wir zunächst außen vor, weil es nur eine Art gibt, wie wir sie vielleicht einmal nutzen und diese ist sehr einfach.
Wir können die Tilde '~' als eine Abkürzung zu unserem Heimatverzeichnis benutzen. Sie muss dann dem entsprechenden Ausdruck vorgestellt sein.
cd ~ Wechsel in das Heimatverzeichnis
cd ~/mydir1 Wechsel in das Unterverzeichnis mydir in meinem Heimatverzeichnis.
Wenn wir nach dem Tildezeichen den Loginnamen eines anderen Benutzers angeben, dann bezieht sich der Befehl relativ auf dessen Verzeichnis. cd ~john wechselt in johns Heimatverzeichnis. Ein vorgestellter Slash zwischen der Tilde und dem Loginnamen des Benutzers ist nicht notwendig, aber natürlich brauchen Sie, wenn Sie nicht der Eigner sind, oder nicht zur Verzeichnisgruppe gehören, die richtigen Zugriffsrechte auf die Verzeichnisse.
Ist das nun alles hinsichtlich der Erweiterung Tilde? Natürlich nicht, dies ist Linux!
Ein Systemverwalter kann sie dazu benutzen, Befehlserweiterungen durch Manipulation des Verzeichnisstacks zuzuweisen - aber das wollen Sie nicht wirklich wissen, oder?
Klammererweiterung ist in Situationen besonders nützlich, wenn eine Abfolge von Dateien oder Verzeichnissen erzeugt oder aufgelistet werden soll.
Die Syntax ist {a,b,c} oder {A..J} oder {1..8}.
Sie können z. B. einen Satz von Verzeichnissen erzeugen, in denen Ihre jährlichen Aufzeichnungen gespeichert sind.

Immer wenn Sie eine Serie von Dingen in einen allgemeinen Ausdruck einbringen wollen, können Sie Klammererweiterungen benutzen.
Zeitverlaufserweiterungen. Bei Eingabe des Befehls history, erhalten Sie eine nummerierte Liste vormals eingegebener Befehle. Einer dieser Befehle wird ausgeführt, wenn Sie !number eingeben (dabei ist number eine der Zahlen der Liste). So funktioniert Zeitverlaufserweiterung in der Praxis. Es gibt dabei noch mehr Möglichkeiten, aber das soll uns im Augenblick nicht interessieren.
Erweiterungen der Shellparameter Diese sind am mächtigsten, wenn sie in Scripts verwendet werden. In ihrer einfachsten Form nehmen sie alles, was auf ein '$' Zeichen folgt und erweitern es auf seine ausführlichste Form. Oft folgt auf das $ Zeichen eine Umgebungsvariable, die ihrerseits zusätzlich in Klammern gesetzt werden kann, z. B. ${var}, es kann auch noch viel mehr sein.
Umgebungsvariablen sind Bezeichnungen für Dinge unseres gegenwärtigen Arbeitsumfeldes, die abrufbar sein müssen. Ein Beispiel hierfür ist, wo wir uns jeweils im Dateisystem befinden. Um das herauszufinden können Sie den Befehl pwd. eingeben.
Diese Information wird in der Umgebungsvariablen PWD gespeichert (hier werden normalerweise Großbuchstaben verwendet, um Variablen von anderem Text zu unterscheiden).
Wenn Sie also den Befehl echo $PWD eingeben wird Parametererweiterung angewendet und der Name der Variablen PWD zum vollen Pfad Ihres gegenwärtigen Verzeichnisses erweitert, bevor er an den Befehl echo weitergegeben wird.
Wenn Sie eine Liste der Umgebungsvariablen und ihres Inhalts sehen wollen, die in Ihrer Systemumgebung gesetzt sind, geben Sie den Befehl env ein.
Einige werden Sie wiedererkennen und Sie können jederzeit eigene hinzufügen, indem Sie den export Befehl in Ihre Datei .bashrc aufnehmen.
export SCRIPTS_DIR="/home/jane/scripts"
Jetzt sorgt der Befehl cp my_new_script $SCRIPTS_DIR dafür, dass es an den richtigen Ort kommt, vorausgesetzt, es existiert...
All diese verschiedenen Wege, mit der die Shell interpretieren kann, was wir eingeben, machen es erforderlich, die Kontrolle darüber zu haben, was wir als was und wann sehen können. Auch wenn die Bash Shell sehr mächtig ist, wollen wir immerhin doch die Kontrolle behalten.
Die Kontrolle über die Shellerweiterungen wird durch den Gebrauch von Anführungszeichen hergestellt. Bei Linux findet man die Anwendung 4 verschiedener Arten von Anführungszeichen:
- “ ”
- Dieser dekorative 66 – 99 Stil wird von Textverarbeitungsprogrammen genutzt. Für uns sind diese Anführungszeichen bedeutungslos
- "
- Standard Doppelanführungszeichen
- '
- Einfache Anführungszeichen
- `
- Back ticks, auch als Accent grave bekannt
Mit den 3 letzteren erzielt man innerhalb der Bash Shell jeweils unterschiedliche Ergebnisse.
Doppelanführungszeichen veranlassen die Shell jegliche Spezialbedeutung von Zeichen innerhalb der Anführungszeichen zu ignorieren, mit Ausnahme von $, ` und \. . Das ist hilfreich, wenn wir der Shell einen Dateinamen übergeben wollen, der ein ungewöhnliches Zeichen oder ein Leerzeichen enthält. Das $ Zeichen wird jedoch nach wie vor interpretiert und damit werden Variable und arithmetische Ausdrücke noch erweitert. Nach der Erweiterung allerdings wird alles andere zwischen den Anführungszeichen an den Befehl als ein Wort übergeben, ohne irgendeinen Buchstaben oder Leerstellen zu verändern. Wie der Back tick interpretiert wird, werden wir gleich sehen, merken Sie sich hier zunächst, dass er nicht verändert wird. Mit dem Backslash können wir das $ und das ` Zeichen umgehen. Dies ermöglicht die Übergabe von Ausdrücken wie "You owe me \$100".

Sehen Sie den Unterschied?
Einzelanführungszeichen stellen die stärkste Form der Nutzung von Anführungszeichen dar. Sie unterdrücken jegliche Erweiterung. Was auch immer Sie zwischen Einzelanführungszeichen setzen, es wird verbatim (wörtlich) weitergegeben, es erfolgt keine wie auch immer geartete Veränderung.
Back ticks ermitteln den Inhalt und setzen ihn ein. Dann wird das Ergebnis an den Befehl übergeben.
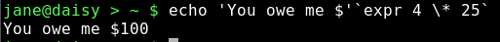
Hier wird 'You owe me $' buchstabengetreu weitergegeben, weil es zwischen Einzelanführungszeichen steht. Der nächste Teil `expr 4 \* 25`, berechnet den Ausdruck 4 * 25 zu 100 und übergibt das an den echo Befehl. Der Backslash vor dem Stern ist notwendig, um die alternative Bedeutung (des Sterns) als Wildcard auszuschließen.
All diese Sachen mit Globbing und Wildcards dürfen nicht mit regulären Ausdrücke (der Shell, oft als regexp) abgekürzt) verwechselt werden, obwohl es gemeinsame Eigenschaften gibt.
Reguläre Ausdrücke sind viel mächtiger. Sie werden verwendet um Daten zu verändern und spezielle Eigenschaften zu überprüfen.
Als wir den grep Befehl benutzten, haben wir schon auf einen regulären Begriff zugegriffen. Der grep Befehl(global regular expression print, vom ursprünglichen Zeileneditor ed der den Befehl g/re/p! nutzte, um Gleiches zu bewirken) hat 2 Brüder egrep und fgrep (es gibt noch einen dritten Bruder rgrep aber man sieht ihn nicht oft).
Den grep Befehl nutzen wir, um in einer Datei ein Muster zu finden, das zu jenem passt, das dem Befehl übergeben wurde. Gleiches gilt für einen Satz von Dateien oder einen Datenstrom (stream of data). Die allgemeine Syntax ist grep {Optionen} {Muster} {Dateien}.
Er kann direkt als Befehl benutzt werden oder aber auch als Ausgabefilter für einen anderen Befehl.
Um in der Datei /etc/passwd Janes Eintrag zu finden können wir entweder grep jane /etc/passwd oder cat /etc/passwd | grep jane verwenden.

In den vorigen Beispielen ist das Muster, für das grep Übereinstimmung sucht, jane.
Reguläre Ausdrücke sind Zeichenfolgen, die die Software benutzt, um ein spezielles Muster an einer speziellen Position in der Zieldatei zu finden.
Warum kümmern wir uns überhaupt um reguläre Ausdrücke?
Für Konfiguration, Ausgaben von Befehlen und Scripten, Berichte über Systemaktivitäten, Sicherheit und eventuelle Probleme verwendet Linux reine Textdateien. Dabei wird eine riesige Menge Text erzeugt. Es gehört zu den wichtigsten Fähigkeiten eines Nutzers der Kommandozeile, diesen Text effizient nach einer bestimmten Information zu durchsuchen.
Zur Nutzung regulärer Ausdrücke stehen uns drei Werkzeuge zur Verfügung:
grep um nach einem Muster zu suchen
sed ist ein Datenstrom (stream) Editor für Filterung und Veränderung von streams. Dies ermöglicht es uns, vorverarbeitete Daten direkt an einen nachfolgenden Befehl, eine Datei oder an stdout/stderr zu übergeben.
awk ist eine Scripting/Programmiersprache, zur automatisierten Suche nach Mustern und für Datenverarbeitung.
Es gibt noch viele andere Befehle, die reguläre Ausdrücke verwenden, wie z. B. tr (translate). Wenn Sie aber die oben genannten drei Werkzeuge zu verwenden gelernt haben, sind Sie auf einem guten Weg, die Kommandozeile auf hohem Niveau zu nutzen.
Bevor wir grep und sed besprechen (awk stellen wir noch zurück, bis wir im Kapitel über das Bashsripting ein wenig Programmieren geübt haben), müssen wir ein gutes Basisverständnis für reguläre Ausdrücke entwickeln. Reguläre Ausdrücke werden von zeilengebundenen Befehlen verwendet und werden daher nicht mit Mustern übereinstimmen, die sich über zwei oder mehrere Zeilen hinziehen. Das sollten Sie vorab schon mal wissen.
In regulären Ausdrücken kommt gewissen Zeichen eine besondere Bedeutung zu. Diese werden Metazeichen genannt. Um ein Metazeichen 'wörtlich zu nehmen' (als das Zeichen, das es darstellt) muss man es 'escapen'. In der Regel geschieht dies durch das Vorstellen eines Backslash, so wie wir das früher auch schon mit den Wildcard Zeichen gemacht haben. Nachstehende Zeichen sind Metazeichen, aber es werden nicht alle von allen Anwendungen anerkannt.
- .
- Der Punkt steht für Übereinstimmung mit jedem einzelnen Zeichen.
- *
- Der Stern steht für kein oder mehrfaches Vorkommen des vorstehenden Zeichens.
- ^
- Das Einschaltungszeichen ist knifflig und hat 2 Bedeutungen. Außerhalb eckiger Klammern steht es für ein Zeichen nur dann, wenn dieses am Anfang einer Zeile steht. Es wird dann Sprungmarke genannt. Steht es hingegen als erstes Zeichen innerhalb eines Klammerpaares, so negiert es Übereinstimmung d. h. "stehe für alles, außer für das, was folgt".
- $
- Another anchor mark this time meaning to only match the pattern at the end of a line.
- \< \>
- Weitere Sprungmarken, stehen für ein Muster am Anfang \< oder Ende \> eines Wortes.
- \
- Das Zitierzeichen oder Escapezeichen, wird verwendet um die spezielle Bedeutung des direkt folgenden Zeichens aufzuheben.
- [ ]
- Eckige Klammern enthalten Gruppen, Bereiche oder Klassen von Zeichen. Eine Gruppe kann auch ein einzelner Buchstabe sein.
- \{n\}
- Steht für n Übereinstimmungen mit dem vorstehenden Zeichen oder regulären Ausdruck. Beachten Sie, dassn Übereinstimmungen mit dem vorstehenden Zeichen oder regulären Ausdruck. Beachten Sie, dass \{2\}, einen Bereich \{2,4\} oder eine kleinste Anzahl \{2,\} (mindestens 2 Übereinstimmungen) stehen kann.
- \( \)
- Aller Text zwischen \( und \) i wird in einem besonderen temporären Puffer gespeichert. Auf diese Weise können bis zu 9 Sequenzen gespeichert und mit den Befehlen \1 bis \9. eingefügt werden. Das wird durch ein Beispiel verdeutlicht.
- +
- steht für mindestens eine Übereinstimmung mit dem vorstehenden Zeichen/regexp. Es handelt sich um eine erweiterte regexp (ERE), siehe später.
- ?
- steht für keine oder mehrere Übereinstimmungen mit dem vorstehenden Zeichen/regexp. Es handelt sich um eine erweiterte regexp (ERE), siehe später.
- |
- steht für Übereinstimmung mit dem vorstehenden oder nachstehenden Zeichen/regexp. Es handelt sich um eine erweiterte regexp (ERE), siehe später.
- ( )
- Wird zur Zusammenfassung regulärer Ausdrücke in Gruppen in komplexen Statements verwendet.
Damit können wir nun jedes Muster an jeder Stelle einer Zeile finden. Manche der Metazeichen haben eine andere Bedeutung, wenn sie dazu verwendet werden, Muster zu ersetzen.
grep
Zuallererst: egrep bedeutet genau das Gleiche wie grep -E und fgrep genau das Gleiche wie grep -F. Wo ist dann der Unterschied?
fgrep arbeitet mit festen Zeichenketten zur Mustererkennung, jedoch überhaupt nicht mit regulären Ausdrücken, damit arbeitet es schneller.
egrep ist eine vollständigere Version von grep. Es gibt 2 Serien von Metazeichen, die von regulären Ausdrücken erkannt werden, BRE und ERE, bzw. Basic Regular Expressions und Extended Regular Expressions. BRE ist eine Untergruppe von ERE. BRE kennt die Metazeichen + ? und | nicht und die Metazeichen () {} müssen mit einem Backslash 'escaped' werden. Zunächst kümmern wir uns um das echte alte grep. Nur der Vollständigkeit halber: rgrep, der andere Bruder ist auch nur grep, das die Verzeichnisse abwärts nach Musterübereinstimmungen durchsucht.
Der grep Befehl verfügt über eine Reihe von Optionen, auf die jeder Linuxbefehl stolz wäre. Im Folgenden beschäftigen wir uns nur mit den Optionen, die von normalen Menschen genutzt werden.
- -A, -B & -C
- gefolgt von einer Zahl – die übereinstimmende Anzahl an Zeilen nach, vor oder um die Übereinstimmung herum ausgeben. Das ist nützlich, Sachen innerhalb einer großen Textdatei zu erkennen.
- -c
- Nur die Anzahl der auftretenden Übereinstimmungen für jede geprüfte Datei angeben.
- -E
- Verwendung der erweiterten Reihe regulärer Ausdrücke (ERE). Das ist das Gleiche, als würde man egrep einsetzen.
- -F
- Keine regulären Ausdrücke verwenden, alle Muster buchstabengetreu behandeln. Das Gleiche wie fgrep.
- -f filename
- Jede Zeile der angegebenen Datei zur Musterüberprüfung verwenden.
- -h
- Bei der Suche in mehreren Dateien, den Dateinamen nicht ausgeben.
- -i
- Groß- und Kleinschreibung ignorieren
- -n
- Zeilennummern ausgeben, für die eine Übereinstimmung gefunden wird.
- -r
- Unterverzeichnisse mit einschließen
- -s
- Fehlermeldungen unterdrücken
- -v
- Die Übereinstimmung invertieren, damit nur Dateien ohne Übereinstimmung gewählt werden.
- -w
- Nur auf Übereinstimmung ganzer Worte prüfen. Wort bedeutet hier einen zusammenhängenden Block von Buchstaben, Ziffern und Unterstreichungszeichen.
Das reicht zunächst. Besuchen wir also die Familie grep und führen einige Beispiele aus.
Nehmen wir an, wir wissen nicht, wie Jane ihren Namen schreibt (jane oder jayne) und wollen den Namen in der Datei /etc/passwd suchen. Dann könnten wir versucht sein das Wildcard Zeichen '*' mit grep j*ne /etc/passwd zu benutzen. Dies wird aber fehlschlagen, da die Shell j*ne erweitert, bevor sie es an grep weitergibt, das reguläre Ausdrücke zur Übereinstimmungsprüfung des Musters benutzt.
Wir könnten grep ja[n,y] /etc/passwd benutzen.

Das würde aber auch Übereinstimmungen mit Namen wie Janet ausweisen.
Um dies zu umgehen, können wir die erweiterte Serie regulärer Ausdrücke verwenden, die mit der -E Option von grep oder mit dem egrep Befehl zugänglich sind. grep -Ew 'jane|jayne' /etc/passwd treffen entweder auf jane oder jayne zu. Die Option -w beschränkt auf vollständige Wörter. Die Klammern werden gebraucht, um zu verhindern, dass die Shell das Zeichen für den senkrechten Strich als Umleitung in eine Pipe interpretiert.

Wie viele Benutzer nutzen die Bash als ihre Standard Shell?
grep -c '/bin/bash' /etc/passwd

Wenn Sie in Ihrem Heimatverzeichnis nach Dateien suchen wollen, die eine Übereinstimmung enthalten, dabei alle Unterverzeichnisse einbeziehen und alle Warnungen bezüglich unzugänglicher Dateien ignorieren wollen, können Sie einen Befehl grep -rs glenn ~/* verwenden.

Komplexe Durchsuchungen können durch die Mehrfachanwendung des grep Befehls vereinfacht werden. Um nach Verzeichnissen zu suchen, die mit dem Großbuchstaben oder dem Kleinbuchstaben 'm' beginnen, verwenden wir ls -l | grep ^\d | grep [M,m]. Dies findet in einer langen zeilengebundenen Verzeichnisliste alle Übereinstimmungen, die mit einem 'd' beginnen (also Verzeichnisse sind.). Die Ausgabe wird dann durch einen weiteren grep Befehl über eine Pipe zum Endresultat umgeleitet.
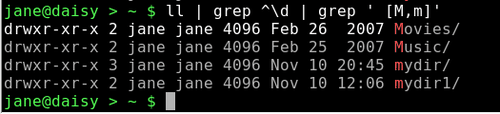
Diese Beispiele zeigen, dass grep ein starkes Werkzeug ist, wenn es darum geht, Informationen aus Dateien oder aus der Ausgabe eines Befehls zu gewinnen. Besonders hilfreich ist das Werkzeug, wenn Sie nicht wissen, wo die Information steht, oder ob sie überhaupt vorhanden ist.
Manchmal wissen Sie genau, welche Informationen es gibt, wollen aber nur einen speziellen Teil davon. Dafür verfügt Linux über einen Befehl, der Ihnen genau das liefert, was Sie wollen.
cut
Richtig nützlich ist der cut Befehl nur bei Dateien mit tabellarischen Daten. Da viele Befehle Daten in diesem Format ausgeben, lohnt es sich wirklich, den Befehl zu kennen, zumal seine Anwendung einfach ist.
Wenn Sie eine Datei mit tabellarischen Daten untersuchen, werden Sie Zeichengruppen finden, die durch ein gleiches, gemeinsames Zeichen voneinander getrennt sind, oft ein Leerzeichen, ein Komma oder ein Semikolon. Dieses gemeinsame Zeichen wird Abgrenzungszeichen (delimiter) genannt und die Zeichengruppen heißen 'Felder'. Der cut Befehl durchsucht jede Textzeile nach dem Abgrenzungszeichen und nummeriert dabei die Felder. Wenn der Befehl das Ende einer Zeile erreicht, gibt er nur die zur Ausgabe verlangten Felder aus. Die allgemeine Form für den cut Befehl ist:
cut {options}{file}
Dabei sind die nützlichsten Optionen:
- -c list
- Nur Zeichen an diesen Positionen wählen
- -d
- Angabe des Abgrenzungszeichens. Wenn nicht angegeben ist der Standard das Tabulatorzeichen tab. Leerzeichen müssen in Anführungszeichen gesetzt werden -d" "
- -f list
- Bezeichnete Felder auswählen
- -s
- Zeilen ohne Abgrenzungszeichen unterdrücken
List besteht aus einer Abfolge von Zahlen, die durch ein Komma getrennt sind oder, wenn ein Bereich gekennzeichnet werden soll, durch einen Bindestrich.
Wenn wir uns eine Zeile aus der Datei /etc/passwd anschauen, stellen wir fest, dass die verschiedenen 'Felder' durch ein Semikolon getrennt sind :.
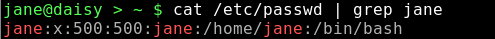
Das erste Feld enthält den login Namen des Benutzers und das fünfte Feld, das aus historischen Gründen gecos Feld heißt (von General Electric Comprehensive Operating System), enthält den 'real name' des Benutzers und manchmal zusätzliche Ortsangaben, die von PCLinuxOS aber nicht verwendet werden.
Um Loginnamen und 'real name' des Benutzers zu erfahren, verwenden wir den Befehl: cut -d: -f1,5 /etc/passwd.
Das veranlasst den Befehl, nach Abgrenzungszeichen zu suchen und den Inhalt der Felder 1 und 5 auszugeben.
Das funktioniert alles sehr gut mit schön angeordneten Daten, wie sie in der Datei /etc/passwd vorliegen, aber in der wirklichen Welt sind die Dinge manchmal nicht so einfach. Nehmen wir z. B. den Befehl ls -l. Der gibt eine schön strukturierte Langliste des Inhaltes des Verzeichnisses aus. Hier ist der Punkt, dass die Ausgabe schön und strukturiert aussieht, dazu versieht der ls Befehl seine Ausgabe mit zusätzlichen Leerzeichen. Wenn unser cut Befehl die Zeile nach Leerzeichen als Abgrenzungszeichen durchsucht, erhöht er jedes mal, wenn er eins findet, den Feldzähler um eins. Dadurch wird die Ausgabe im besten Fall unvorhersagbar. Viele Linux Befehle unterfüttern ihre Ausgaben in dieser Art und Weise. Dafür ist der ps Befehl ein weiteres Beispiel.

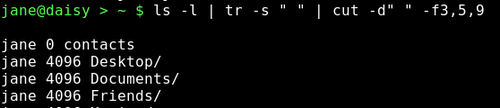
Wenn ich aus dieser Liste den Namen des Eigners, Dateigrößen- und Namen herausfiltern will, scheint es angebracht, die Felder 3,5 & 9 herauszuziehen und als Abgrenzungszeichen ein Leerzeichen zu vermuten.
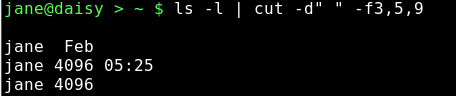
Wie Sie sehen, erfüllt die Ausgabe nicht unsere Erwartungen. Wir könnten es mit der -c Option versuchen und damit Felder und das Zählen von Zeichen vom Zeilenbeginn an verhindern.
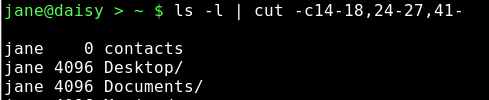
Aber das ist mühsam und fehlerträchtig. Wenn sich die Verzeichnisliste nur geringfügig ändert, dann ändern sich auch die Zahlen und der Code lässt sich nicht wiederverwenden, wir müssten von vorne beginnen.
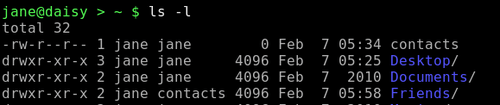
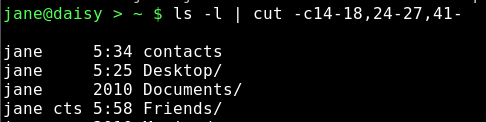
Um dies zu umgehen, müssen wir die Ausgabe des ls Befehls durch Ausfiltern der zusätzlichen Leerstellen vorbereiten. Das können wir mit Hilfe eines Befehls bewerkstelligen, den wir schon einmal kennen gelernt haben. Der tr Befehl übersetzt Daten und wir haben ihn vorher benutzt, um Text aus Kleinbuchstaben in solchen aus Großbuchstaben umzuwandeln. Wenn wir den Befehl tr mit der -s Option, gefolgt von einem Leerzeichen benutzen, werden aufeinanderfolgende Leerzeichen aus der Datei oder dem Datenstrom zu einem einzigen (Leerzeichen) verschmolzen.
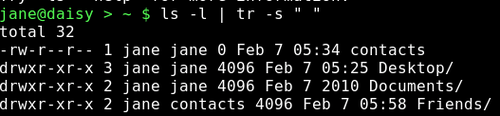
Jetzt können wir genau die Daten ausschneiden, die wir wollen.
Zwei weitere einfache, aber nützliche Befehle, die Erwähnung finden sollen, sind paste und join. Geben wir den Befehl gefolgt von --help ein, so erhalten wir ausreichende Informationen zur Befehlsanwendung, aber ein einfaches Beispiel soll ihre Nützlichkeit und ihre Unterschiede besser verdeutlichen.
Nehmen wir an, wir hätten zwei Dateien, die unterschiedliche Daten enthalten, aber gemeinsame Eigenschaften haben wie z. B.:
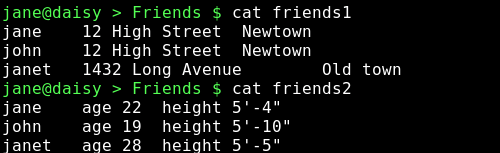

Die Namen dieser Dateien sind die gleichen, aber die Inhalte sind verschieden. Die Daten beider Dateien können wir mit join zusammenführen.
paste fügt zeilenbasiert Daten ans Ende einer Datei an, die wir aus einer anderen Datei ausgeschnitten haben (cut).

sort
Wenn Sie nun die gewünschten Daten gefunden, alle unerwünschten Informationen herausgeschnitten und die Ergebnisse zusammengefügt haben, dann weisen diese vielleicht noch nicht die von Ihnen gewünschte Reihenfolge auf. Um diese herzustellen, verfügt Linux über ein ausnehmend mächtiges und schnelles Hilfsmittel.
Die Syntax des sort Befehls ist sort {options} {file(s)}. Wenn mehr als eine Datei angegeben ist, dann wird der kombinierte Inhalt der Dateien sortiert und ausgegeben.
Die für den sort Befehl verfügbaren Optionen machen ihn zu einem ziemlich verständlichen Hilfsmittel. Die am meisten gebräuchlichen sind:
- -b
- Führende Leerstellen des Sortierfeldes ignorieren
- -c
- Nur prüfen, ob die Daten sortiert sind, aber nicht sortieren
- -d
- Sortieren nach der Ordnung von Wörterbüchern (in sich alphabetisch), nur Leerzeichen und alphanumerische Zeichen in Betracht ziehen
- -f
- keine Unterscheidung zwischen Groß- und Kleinschreibung
- -i
- Nur darstellbare Zeichen in Betracht ziehen. Diese Option wird ignoriert, wenn die -d Option gesetzt ist.
- -k
- Sortierfeld angeben
- -n
- nach Zahlen sortieren (numerische Sortierung)
- -r
- Sortierreihenfolge umkehren
- -t
- Das Feldertrennzeichen angeben
- -u
- Von mehreren identischen Zeilen nur die erste ausgeben. Wenn die -c Option gesetzt ist, überprüfen dass keine identischen Zeilen vorhanden sind.
Einige dieser Optionen erfordern zusätzliche Erläuterungen.
Der Befehl sort unterscheidet bei Feldbegrenzungszeichen nicht so detailliert wie z. B cut. Soweit sort betroffen ist, werden Felder durch Leerzeichen getrennt, unabhängig davon, ob diese irgendwelche nicht darstellbare Zeichen enthalten oder nicht. Das ist im Prinzip keine schlechte Idee, aber es gibt Fälle bei denen Probleme auftreten, wie z. B. in /etc/passwd, die keine Leerzeichen enthält. In diesen Fällen kann das Feldtrennungszeichen mit der Option -t angegeben werden. Mit Sort -t: -k5 /etc/passwd erreichen wir, dass sort nach der 5ten Spalte (voller Name des Benutzers) sortiert und diese Spalte verwendet, um Anfang und Ende der Felder zu bestimmen.
Sortierfelder zu spezifizieren war gewöhnlich eine unklare Angelegenheit, mit der -k Option geht es nun ziemlich geradlinig.
-k {Zahl} Spezifiziert das Feld in der Position {Zahl}.
Die Nummerierung startet mit 1. Komplexere Argumente für die Sortierung der Felder können angegeben werden, wie z. B. mit welchen Zeichen innerhalb des Feldes der Sortiervorgang starten oder enden soll. Mein Ansatz hierfür ist, dass man so etwas lernen sollte, wenn man es braucht. Man braucht es nämlich nur selten und sollte seinen Denkapparat nicht mit überflüssigen Dingen belasten.
ls -l | sort -k9 sortiert das Listing eines Verzeichnisses nach dem 9ten Feld (Dateiname) in Wörterbuchordnung.
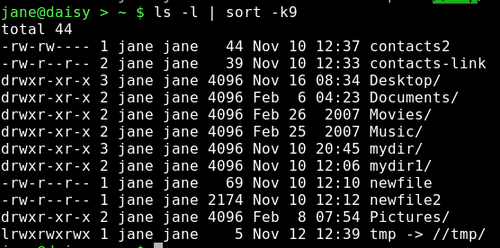
ls -l | sort -nrk5 sortiert das Listing nach dem 5ten Feld (Dateigröße) in umgekehrter numerischer Reihenfolge.

Mit ein wenig Praxis kann man mit diesen wenigen Befehlen unwahrscheinlich viel machen. Wenn Sie noch mehr wollen, dann gibt es das natürlich auch noch. Hier kommt der sed stream Editor ins Spiel. Dieser ermöglicht gleichzeitiges Suchen, Ersetzen, Einfügen, Löschen, Substitution und Übersetzung von mehreren Dateien. Wenn es das ist, was Sie wollen, dann können Sie sed als ein einfaches Substitutionswerkzeug verwenden, oder seine Anwendung so komplex handhaben, wie es Ihnen passt. Wir werden sed bald kennen lernen.



