Einführung: Schnittstelle Kommandozeile Teil 3
von Peter Kelly (critter)
In den beiden ersten Folgen dieser Einführung haben wir gelernt, wie man mit Dateisystemen umgeht, wie man Dateien erzeugt und editiert, wie man manche der gebräuchlichsten Linuxbefehle anwendet und wie man Einiges vom lästigen (Ein)Tippen verringern kann. Das Umfeld der Kommandozeile ist jetzt für Sie hoffentlich nicht mehr abschreckend. Es gibt ein wenig mehr Theorie, die wir abdecken müssen, aber die ist nicht zu schwierig und es macht auch nichts aus, wenn Sie nicht alles verstehen. Wenn Sie an einen Punkt kommen, wo Sie diese Information brauchen, dann können Sie sagen hey, ich habe was darüber gelesen. Und dann können Sie hierher zurückkommen, oder im Internet danach suchen. Wichtig ist, dass Sie eine Einführung erfahren haben, dass die Information existiert und Sie damit einen Wegweiser nach vorne haben. Wenn Sie bisher folgen konnten und auch diesen Einführungsteil überstehen, dann haben Sie einen guten Eindruck davon, womit Sie es bei Linux zu tun haben. Dann können wir anfangen, die wirkliche Macht der Linux Kommandozeile zu nutzen, die Sie nie mit einem GUI alleine ausschöpfen können.
Ein neuer Name
Als Jane ihren Computer bekommen hat, beschloss Sie ihn 'home' zu nennen. Letztendlich ist es ja der Computer, den Sie zu Hause benutzt. Da gibt es aber einige Nachteile. Was passiert, wenn der Computer in ein Netzwerk eingebunden werden soll und wenn ihr Bruder John seinen Computer auch 'home' genannt hat? Dann wären 2 Computer mit dem gleichen Namen 'home' im Netz und das kann ja ganz offensichtlich nicht in Ordnung sein. Manchmal verwechselt Jane auch, wenn Sie Ihren Prompt sieht, dass sie in ihrem Heimatverzeichnis ist, was nicht der Fall sein muss. Ändern wir all dies.
Jane beschließt, dass ihr Computer 'daisy' heißen soll.
Im Netzwerk bezeichnet man den Namen eines Computers mit 'hostname'. Wenn kein Name zugewiesen wurde, dann wird der Name localhost (das bedeutet dieser Computer) angezeigt. Jede Veränderung hiervon muss bei PCLinuxOS an zwei Stellen, mit Root Privilegien, durchgeführt werden. Mit 'localhost' bezieht sich der Computer intern auf sich selbst, in etwa so, als würde er 'ich' sagen. Um dem Computer zu verstehen zu geben, dass sich der neue hostname daisy auf ihn bezieht, müssen wir ein Alias erzeugen. Es ist so als stünde daisy für localhost.
Die erste Datei, die editiert werden muss hat den Namen hosts und befindet sich im Verzeichnis /etc. Man kann dies auf zwei Arten durchführen: die Datei direkt editieren, oder das PCLinuxOS Control Center benutzen. Beim PCLinuxOS Kontrollzentrum, auch PCC genannt, handelt es sich um ein Frontend für mehrere, kleinere grafische Hilfsmittel, die ein wenig der Kommandozeilenarbeit für Sie übernehmen und deren Namen meistens den Begriff 'drak' beinhalten. Wir zeigen einen Punkt auf:
cat /etc/hosts
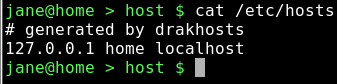
Wenn Sie sie nie verändert haben, wird Ihre hosts Datei ein wenig anders aussehen. Geben Sie drak ein und dann Tab, um sich die verfügbaren Befehle anzeigen zu lassen. Der Befehl, den wir wollen, ist drakhosts (die Einstiegsseite ist drakconf). Geben Sie 'ho' ein und dann Tab, um den Befehl zu vervollständigen und dann ENTER. Wenn Sie das als normaler Benutzer ausgeführt haben, dann werden Sie nach dem Root Passwort gefragt.
Jetzt erhalten Sie diese Bildschirmanzeige.
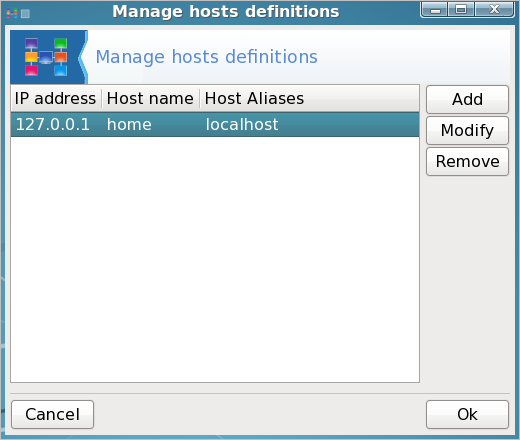
Beachten Sie, dass es drei Spalten gibt: IP Adresse, hostname und host aliase. Wählen Sie localhost und klicken Sie dann auf modify.

Geben Sie im Eingabefeld für Host name den Namen ein, von dem Sie wollen, dass es Ihr Computername wird (Jane hat den Namen daisy gewählt) und im Eingabefeld für die Host Aliases geben Sie localhost ein (Kleinbuchstaben, keine Leerzeichen). Klicken Sie dann Ok in der Box mit dem Änderungsdialog und dann in der drakhosts Box, um zurück zur Kommandozeile zu gelangen.
cat /etc/hosts

Beachten Sie, dass der Inhalt (der Ausgabe) sich verändert hat. Die meisten der PCC Hilfsmittel sind nichts anderes, als raffiniert editierte Systemkonfigurationsdateien.
Jetzt weiß dieser Computer, dass wir uns auf ihn beziehen, wenn wir ihn mit daisy ansprechen. Nun müssen wir noch sicherstellen, dass dies auch alle anderen Computer im Netzwerk wissen.
Achten Sie auf die IP Adresse. Das ist die Sequenz aus 4 Zahlen am Anfang. Localhost besitzt immer die Sequenz 127.0.0.1 – so übersetzt der Computer 'ich'. Computer sprechen in Zahlen. Mit einer IP Adresse beziehen sich Computer aufeinander. In einem Netzwerk ist ein Computer durch die IP Adresse bekannt, die seiner Netzwerkschnittstelle zugewiesen wurde. Normalerweise ist das irgend etwas wie 192.168.0.1. Das kann man sich nur schlecht merken, also geben wir dem Computer einen 'richtigen' Namen wie daisy, den wir uns leichter merken und als Netzwerkreferenz verwenden können.
Die zweite Datei, die verändert werden muss, heißt network. Sie befindet sich im sysconfig Verzeichnis, welches ein Unterverzeichnis von /etc ist.
Wir werden uns des Terminals bedienen, um diese Datei zu verändern.
su (ENTER).
Das Passwort für root eingeben.
nano /etc/sysconfig/network öffnet diese Datei für's Editieren. Fügen Sie eine Zeile mit HOSTNAME=daisy hinzu, oder ändern Sie diese Zeile (egal, welchen Namen Sie auswählen). Achten Sie auf die Großbuchstaben und Abwesenheit von Leerzeichen.
Geben Sie ENTER ein und dann Ctrl-x um die Datei zu speichern und das Programm (nano) zu verlassen. Job ausgeführt! - Im Stil der Kommandozeile.
Das war's, aber wir müssen neu booten, um die Änderungen wirksam werden zu lassen.

Dinge finden
Wenn man mit Dateien arbeiten will, muss man wissen, wo sie stehen, oder wie man sie finden kann. In Linux gibt es viele Wege an diese Informationen zu gelangen. Schauen wir uns also einige an und arbeiten damit.
locate Dieser Befehl nutzt eine Datenbank über Dateien, die dem System bekannt sind, um herauszufinden, wo sie stehen. Diese Datenbank wird täglich automatisch mit Hilfe des Werkzeugs cron vom System aktualisiert. Cron werden wir noch rechtzeitig kennenlernen. Man kann die Datenbank auch jederzeit mit dem Befehl updatedb aktualisieren. Der Befehl updatedb benötigt Root Privilegien, während der locate Befehl diese nicht braucht.

Um die Farbe unseres Prompts zu ändern, haben wir die Datei .bashrc editiert. locate hat 3 Dateibelege dort gefunden: Jane's, John's und den, der für die Anlage eines neuen Benutzerkontos verwendet wird. Ein Vorteil von locate ist, dass der Befehl sehr schnell ist. Der Nachteil ist, dass er nur Dateien kennt, die in der Datenbank gespeichert sind.
whereis – dieser Befehl sucht ausschließlich nach Linux Befehlen und den damit verbundenen Quell- und Dokumentationsdateien.

Hier sind die Binärdatei (der tatsächliche ls Befehl) und die dazugehörige komprimierte manual Dokumentationsdatei ausgegeben.
find — ein äußerst mächtiger Befehl mit einer etwas komplexeren Syntax als die meisten anderen Linux Befehle. Die meisten Leute (das sind auch wir) brauchen nur einen ganz kleinen Teil der Mächtigkeit, die dieser Befehl zur Verfügung stellt. Wir werden also nicht zu tief auf alle Register und Pfeifen schauen – noch nicht.
Standardmäßig benutzt find das aktuelle Verzeichnis für seinen Input und STDOUT (den Bildschirm) für die Ausgabe. Verwendet man die Option 'all files', so erzeugt find dieselbe Ausgabe, wie der Befehl ls -aR von der Kommandozeile aus, wenn auch in einem leicht unterschiedlichem Format. Probieren Sie es aus. Diese vollständige Ausgabe bedeutet, dass find, ohne Optionen, sich alle Dateien in seinem Ausgangsverzeichnis anschaut. Das beinhaltet die versteckten Dateien und auch, rekursiv, alle Unterverzeichnisse. Ausgegeben werden dann diejenigen Dateien, auf die die Suchkriterien zutreffen, in unserem Fall 'all files'.
Um den find Befehl verwenden zu können, müssen wir ihn kontrollieren. Die gebräuchlichste Art, mit find den Ort von bestimmten Dateien oder Dateigruppen aufzufinden sieht so aus:
find {wo nachsehen} {Suchkriterien} {Dateiname(n)}
Es gibt eine Menge Dinge, die unter Suchkriterie(n) angegeben werden können, aber in der Regel suchen wir nach einem Dateinamen. Also, um eine Datei mit Namen network zu suchen, von der wir glauben, dass sie sich irgendwo innerhalb der Struktur des /etc Verzeichnisses befindet, werden wir unseren Befehl so formulieren:
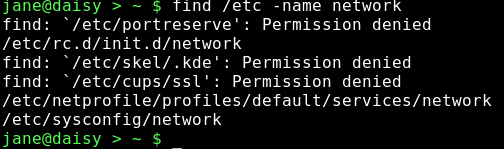
Hier wurden 3 Dateien mit Namen network gefunden und ihre Position (Lage im Dateisystem) wird angegeben. Unglücklicherweise werden auch einige Fehlermeldungen ausgegeben. Das Verzeichnis /etc ist ein Systemverzeichnis und es gehört als solches nicht Jane. Für Jane sind nur Dateien in solchen Verzeichnissen sichtbar, für die sie vom System Leseerlaubnis erhalten hat. Als wir Umleitung (redirection) besprochen haben, habe ich STDIN und STDOUT erklärt und auch einen dritten Datenstrom namens STDERR erwähnt. Auf diese drei Datenströme kann man sich auch mit Hilfe der Zahlen 0, 1 und 2 beziehen. Unter Nummer 2, STDERR legen Programme ihre Fehlermeldungen ab. Je nach Programm können die in eine Logdatei geschrieben werden, oder nach STDOUT, wie das hier der Fall war. Um diese Meldungen zu unterdrücken, können wir STDERR nach irgendwo anders hin umleiten. Unter Linux werden Geräte wie Dateien behandelt. Wir können von ihnen lesen, oder sie beschreiben, wie wir es auch mit einer Datei machen würden. Geräte haben Namen, wie /dev/cdrom oder /dev/hda1, aber es gibt auch ein ganz spezielles Gerät, das /dev/null heißt. /dev/null verhält sich wie ein schwarzes Loch, das alles verschlingt, was man auf es schreibt, ohne jemals wiedergesehen zu werden. Gleichzeitig erhalten Sie nichts, wenn Sie etwas von /dev/null lesen, beziehungsweise Sie erhalten einen Datenstrom von nichts oder einen Nulldatenstrom. Nicht die Zahl 0, sondern das Zeichen, das ein Dateiende kennzeichnet und das EOF genannt wird. Um die Datenausgabe beizubehalten und die Fehlermeldungen umzuleiten, lassen wir den Datenstrom 1, wie er ist und fangen Datenstrom 2 (STDERR) mit der Direktive 2>/dev/null ab.
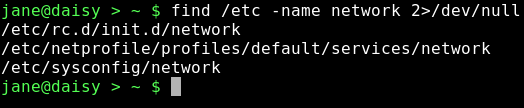
Hübsche, saubere Ausgabe.
Wenn Sie den genauen Namen der Datei nicht kennen, die sie suchen, können Sie 'wild cards' benutzen. Dabei handelt es sich um spezielle Zeichen, die die Shell unterschiedlich interpretiert. Die gebräuchlichsten sind:
- '*' bedeutet 'ersetze hier null oder mehr unbekannte Zeichen'
- '?' bedeutet 'ersetze hier genau ein unbekanntes Zeichen'
Es gibt noch eine Menge mehr, aber die werden wir später behandeln, wenn wir zu den regulären Ausdrücken kommen. Für unsere gegenwärtigen Bedürfnisse genügen diese beiden vorläufig.
Linux – Die Grundlagen
Tatsächlich versteht Linux nur zwei Dinge: Dateien und Prozesse. Wem diese Aussage recht radikal und kühn erscheint, der sollte sich Folgendes vergegenwärtigen: was auch immer wir an einem Computer tun, es beinhaltet die Arbeit mit Dateien. Wir erzeugen, löschen, editieren sie und benennen sie um. Wir schneiden sie auseinander, fügen sie zusammen und durchsuchen sie nach einer bestimmten Information. Kurz, wir machen alles Mögliche mit Dateien, um unser gewünschtes Resultat zu erzielen. All dies machen wir indem wir Prozesse anwenden.
Es gibt mehrere Dateitypen.
- Reguläre Dateien. Diese können unterteilt werden in:
- Datendateien wie Textdateien, Bild- oder Musikdateien
- Ausführbare Scripts – für Menschen lesbare Befehlslisten, die sequentiell abgearbeitet werden (jedoch manchmal mit intelligenter Durchführungsplanung, die es schwierig macht, sie zu verfolgen).
- Binärdateien, die in vom Computer lesbarer Form vorliegen und direkt ausgeführt werden können. Dabei handelt es sich um die Anwendungen, die wir einsetzen und Bibliotheken mit Routinen und Funktionen, auf die sich die Anwendungen beziehen können. Der Inhalt ist für Menschen meist unverständlich.
- Verzeichnisse. Tatsächlich sind dies Dateilisten, die auch über mehrere Festplattenlaufwerke verteilt sein können und die zu unserer Bequemlichkeit in Gruppen zusammengefasst sind.
- Links (Verknüpfungen). Das sind Zeiger auf eine eigentliche Datei. Es kann viele Links auf jede Datei geben.
- Spezielle Dateien. Diese braucht Linux, um mit dem System zu kommunizieren und um mit der Hardware wechselwirken zu können. Sie sind hauptsächlich im Verzeichnis /dev zu finden. Bei Linux wird auch Ihre Maus wie eine Datei behandelt.
- Sockel. Im Augenblick ignorieren wir diese.
- Benannte Tunnel (pipes). Siehe oben. Die kommen später noch dran.
Wenn wir eine ausführbare Datei anklicken, oder ihren Namen auf der Kommandozeile eingeben, dann startet der Kernel einen Prozess, der hoffentlich solange läuft, bis er entweder durch den Benutzer, oder durch auslaufen des Prozesses beendet wird. Jeder Prozess erhält eine Identität in Form einer Zahl, die man 'Prozess ID' nennt. Der Prozess kann aber umgekehrt auch jegliche Anzahl von Unterprozessen starten.
Wenn ein ursprünglicher Prozess beendet wird, dann werden alle mit diesem verbundenen, nicht mehr benötigten Prozesse, ebenfalls beendet, alle Systemresourcen wie zugewiesener Speicher und die Prozess id freigegeben und offene Dateien geschlossen. Gelegentlich verlaufen die Dinge nicht ganz nach Plan und die Systemressourcen werden knapp. Das führt dann dazu, dass das System langsamer wird, bis irgend jemand interveniert. Rebooten des Systems löst das Problem, ist aber nicht immer bequem. Es handelt sich um ein Multiusersystem. Das Herunterfahren eines solchen verzweigten Systems würde zu viel Unterbrechungen bewirken. Es gibt andere Wege, damit umzugehen.
Das ist der Grund, warum wir uns mit Dateien und Prozessen auskennen müssen.
Links (Verknüpfungen)
Jetzt ist vielleicht der richtige Zeitpunkt, über Links zu sprechen. Es gibt zwei verschiedene Arten von Links: harte Links oder weiche Links, auch symbolische Links oder Symlinks genannt. Ein weicher Link ähnelt einem Shortcut in Windows. Dabei handelt es sich um einen Zeiger auf einen Dateinamen, der sich im gleichen Verzeichnis befinden kann, oder häufiger, irgendwo tief in einer anderen Verzeichnisstruktur vergraben ist. Es handelt sich dabei um einen bequemen Weg auf Dateien zuzugreifen, ohne dass man die ganze, voll qualifizierte Adresse der Datei eingeben (oder auch kennen) muss. Nehmen Sie an, dass Sie eine Datei namens contacts haben, die mehrere Ebenen tief in Ihrem Heimatverzeichnis liegt und auf die sie leicht von Ihrem Heimatverzeichnis aus zugreifen können wollen.
Richten wir das ein.
cd ~
mkdir -p mydir/personal/mycontacts
Die -p Option teilt hier dem mkdir Befehl mit, alle Elternverzeichnisse, wie verlangt zu erzeugen.
mv contacts mydir/personal/mycontacts verschiebt die Datei contacts, die wir zuvor erzeugt haben, in das neue Verzeichnis.

Die Datei kann nicht gelesen werden, weil wir sie in unser neues Verzeichnis verschoben haben.
ln -s mydir/personal/mycontacts/contacts link-to-contacts erzeugt einen weichen Link (-s) zu dieser Datei und dann kann auf sie über link-to-contacts zugegriffen werden.
cat link-to-contacts gibt den Inhalt von /home/jane/mydir1/personal/mycontacts/contacts am Bildschirm aus.

Die Syntax für den ln Befehl lautet wie folgt: ln {-s wenn ein soft Link} {was Sie verlinken wollen} {Name des Link}
Das System macht umfangreichen Gebrauch von Symlinks und jede Datei kann vielfach verlinkt werden. Wenn die Originaldatei aus dem Verzeichnis mycontacts gelöscht wird, dann bleibt der Link in meinem /home Verzeichnis stehen, aber cat contacts liefert jetzt die Meldung 'No such fole or directory'. Dieses nennt man einen gebrochenen Link. Wenn wir den Befehl ls -l eingeben, dann wird die Ausgabe für diesen Link in blinkendem rot-weißem Text ausgegeben (andere Distributionen können andere Farben verwenden).
Harte Links zeigen nicht auf einen Dateinamen, sondern enthalten vielmehr eine Referenz zu etwas, das Inode genannt wird. Wenn eine Datei erzeugt wird, weist ihr das Dateisystem eine Zahl zu, einen Inode. Diese Zahl zeigt für das Dateisystem auf einen Satz von Metadaten bzw. Information über die Datei, ihre Berechtigungen, ihren Namen und wo die Daten auf der Platte gespeichert sind usw. Jeder Inode auf einer Partition ist einzigartig und kennt nur eine einzige Datei, jedoch bezieht sich dieselbe Inodezahl auf zwei verschiedenen Partitionen oder Festplatten auf unterschiedliche Sätze von Metadaten und damit auf unterschiedliche Dateien. Stellen Sie es sich so vor, als bestünde eine Datei aus zwei Abschnitten: der Abschnitt mit den Metadaten referenziert sich über den Inode, und der Datenabschnitt referenziert sich über die Metadaten. Normalerweise brauchen Sie über Inodes nichts zu wissen, da das Dateisystem alles für Sie erledigt.
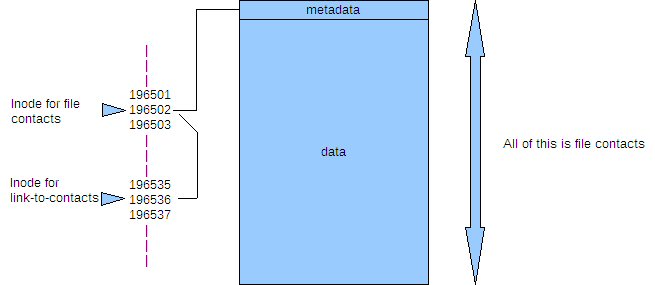
Sie können diese Zahlen sehen, wenn Sie den Befehl
ls -i
eingeben.

cd mydir/personal/mycontacts

Ein harter Link ist so etwas, wie ein anderer Name für die Datei, er erbt aber die ursprüngliche DNA. Das Erstellen eines harten Links geht genau so, wie das für einen weichen Link, aber ohne das -s. Wenn eine Datei erzeugt wird, wird die Anzahl der Links für den Inode auf 1 gesetzt. Erzeugt man nun einen harten Link, so wird die Anzahl von Links auf diesen Inode um eins erhöht. Wird ein harter Link oder die Originaldatei gelöscht, dann wird der Zähler wieder um eins verringert. Wenn der Linkzähler 0 erreicht – und nur dann – wird der Inode und der Speicher für die Abschnitte der Metadaten und der Daten freigegeben. Die Datei ist gelöscht.
ln ~/mydir/personal/mycontacts/contacts contacts-link erzeugt einen harten Link mit Namen contacts-link.
ls -i

Beachten Sie, dass die Inodes für beide die Gleichen sind, für den Link und für die Datei, i. e. 965021.
cat contacts-link
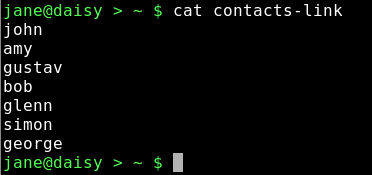
rm mydir/personal/mycontacts/contacts löscht die ursprüngliche Datei.

cat contacts-link
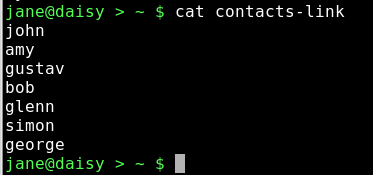
Obwohl die Datei gelöscht wurde, zeigt der Link immer noch auf den Inode. Er kann daher auf die Daten zugreifen, die noch nicht gelöscht sind. Während man dies als Sicherheitsalbtraum ansehen kann, so hat es doch den Vorteil, dass wichtige Dateien von ungeschickten Händen angesprochen werden können. Man kann nun beruhigt sein, dass der Link zu den Daten der Datei leicht wiederhergestellt werden kann und ein Datenverlust nicht auftreten muss.
(Datei)Rechte & Gruppen
Unix, von dem Linux ein Ableger ist, ist als Multiusersystem konzipiert. Es musste also eine Methode entwickelt werden, mit der festgestellt werden kann, wer auf welche Dateien zugreifen darf. Manche Dateien sind privater Natur, andere müssen anderen Benutzern zugänglich sein und wieder andere können öffentlich (allen zugänglich) sein. Man muss auch betrachten, wie weit ein Zugriff gehen soll: dürfen die Benutzer den Dateiinhalt verändern, oder die Datei löschen oder, wenn es sich um eine ausführbare Datei handelt, wer darf sie starten?
Standardmäßig ist ein Benutzer, der eine Datei erstellt auch ihr 'Besitzer'. Sie gehört dann auch zur primären Gruppe des Benutzers, aber dies kann man ändern. Manche Benutzer erzeugen Dateien und möchten, dass eine Gruppe anderer Benutzer auf sie zugreifen kann. Wieder anderen Benutzern soll der Zugriff verweigert sein. Dafür wurden Benutzerrechte auf drei Ebenen eingeführt:
- Leserechte
- Schreibrechte
- Rechte zum Ausführen (im Falle eines Verzeichnisses, das Recht hineinwechseln zu können)
Jedes dieser Rechte kann eingeräumt oder entzogen werden und zwar
- dem Eigentümer
- der Gruppe
- edem anderen
Bei regulären Dateien sind die Rechte ziemlich offensichtlich. Bei einem Verzeichnis bedeutet Leserecht, dass Sie den Inhalt (Dateinamen oder Namen von (Unter)verzeichnissen) auflisten dürfen, Schreibrecht bedeutet, dass sie Dateien des Verzeichnisses löschen oder umbenennen, sowie neue Dateien erzeugen dürfen und Ausführungsrechte bedeuten, dass Sie mit 'cd' in dieses Verzeichnis wechseln dürfen.
Schauen wir uns das Listing eines Verzeichnisses mit ls -l an:
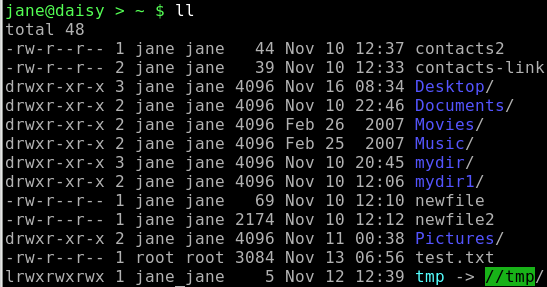
Auf der ersten Position von links wird der Dateityp angegeben. Dies kann einer der nachstehenden sein:
— reguläre Datei oder harter Link
d Verzeichnis
l weicher (symbolischer) Link
p benannter Tunnel
s Sockel
c Zeichentunnel
b Blockgerät
Die nächsten 9 Positionen sagen etwas über die Dateirechte aus. Bei den ersten drei Positionen handelt es sich um Benutzerrechte, die nächsten drei regeln die Gruppenrechte und die letzten drei die anderen Rechte, die auch Weltrechte genannt werden. Die Lese- Schreib- und Ausführungsrechte werden wie folgt dargestellt:
Benutzer Gruppe andere (Welt)
r w x r- - r - -
In diesem Beispiel darf der Benutzer die Datei lesen ändern und ausführen, während Andere nur den Inhalt betrachten dürfen. Das Lese- und Schreibrecht wird durch 'r' bzw. durch 'w' gekennzeichnet, wogegen das Ausführungsrecht nochmal in 'x', 's' oder 't' unterteilt ist.
x die normale Ausführungserlaubnis
s suid Benutzer id gesetzt
t 'sticky' bit gesetzt
Die letzten Beiden werden von normalen Benutzern kaum gebraucht, wir lassen sie also vorläufig weg. Die Rechte für eine Datei können von Root oder vom Benutzer geändert werden. Der Befehl hierfür sieht so aus:
chmod {Optionen} {Rechte} {Datei- oder Verzeichnisname}
Den Rechtebereich des o. g. Befehls können Sie auf zwei Arten verändern.
Sie können 'u', 'o', 'g' und 'a' benutzen, um festzulegen, welcher Rechtesatz geändert werden soll. Dabei stehen 'r', 'w' und 'x' für die Rechte und '+', '-' oder '=' für deren Setzen oder nicht Setzen. Zusätzlich können Sie diese kombinieren, um mehr als Eines zu ändern. Vermeidet man u, g oder o, dann werden die angegebenen Rechte auf allen Positionen gesetzt oder entfernt.
Beispiele: Wenn myfile die Rechte rw- r-- r-- besitzt, dann führen folgende Befehle dazu, dass
- chmod g+w Schreibrechte für die Gruppe eingeräumt werden, i. e rw- rw- r--
- chmod o+w Schreibrechte für andere hinzugefügt werden, i. e. rw- rw- rw-
- chmod +x Ausführungsrechte für alle hinzugefügt werden, i. e. rwx rwx r-x
- chmod ug-w die Schreibrechte für den Benutzer und die Gruppe entfernt werden, i. e. r-x r-x r-x
- chmod ugo=rw Schreib- und Leserechte für alle gesetzt werden, i. e. rw-rw-rw-.
Bei der zweiten Art, Rechte zu kennzeichnen, werden Zahlen benutzt. Zahlengesteuerte Rechte werden so gesetzt:
Lesen=4, Schreiben=2 und Ausführen=1.
Dazu wird das Oktalsystem verwendet (ein auf 8 basierendes Zahlensystem). Um dieses zu benutzen brauchen wir es an dieser Stelle jedoch nicht zu verstehen. Anstelle von 'r', 'w', 'x' verwenden wir '4', '2' und '1'. Um diese zu kombinieren, können wir sie aufaddieren. Somit wird rw = 4+2 = 6.
Wenn wir dies auf die 3 Gruppen anwenden, dann verwenden wir die 3 Summen. 'rwx rw- r--' wird dann zu (4+2+1) (4+2+0) (4+0+0) = 764.
Manchmal wird das auch als 0764 geschrieben. Kümmern Sie sich nicht um die vorangestellte Null, die hat etwas mit dem Oktalsystem zu tun und für unsere Belange ist es gleichgültig, ob sie dabeisteht, oder nicht.
Um also die Rechte auf rw- r-- zu setzen, verwenden wir den Befehl chmod 664 myfile1.
Schauen wir noch einmal auf die Verzeichnisliste. Nach den Rechten findet man eine Zahl, die die Anzahl der Links oder Referenzierungen auf diese Datei angibt. Danach finden wir den Namen des Besitzers der Datei und anschließend den Namen der Gruppe, zu der die Datei gehört.
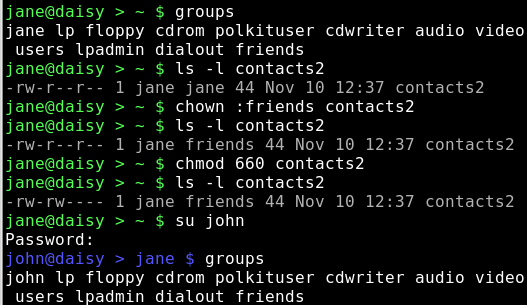
Für eine Auflistung aller Gruppen sehen wir in /etc/group nach.
cat /etc/group
Um herauszufinden, zu welchen Gruppen jemand zugehörig ist, benutzen wir den Befehl
groups username

Das Hinzufügen einer neuen Gruppe erfordert Root Rechte und Eingabe des Befehls 'groupadd'.
su (Root Passwort eingeben) groupadd friends
fügt die neue Gruppe 'friends' in der Datei /etc/group hinzu.
Um einer Gruppe Benutzer hinzuzufügen verwendet man den Befehl usermod. Die -a Option bedeutet append (erweitern).
usermod -aG friends jane (großes G beachten)
usermod -aG friends john
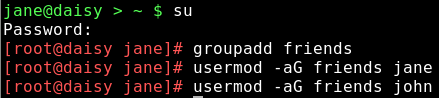
macht jane und john zu Mitgliedern der Gruppe friends. Dies wird beim nächsten Login wirksam.
Um eine Datei den Mitgliedern einer Gruppe zugänglich zu machen, können wir den Befehl 'chown' (Besitzer ändern) verwenden.
chown jane:friends contacts2
Dies behält jane als Dateibesitzer bei, ändert aber die Gruppenmitgliedschaft.
Da wir nur die Gruppe ändern wollten, hätten wir es auch mit
chown :friends contacts2
durchführen können.
Mit dem Befehl
groupdel groupname
werden Gruppen gelöscht.
Dies lässt alle Dateien, die zu dieser Gruppe gehörten, verwaist zurück. Es bleibt Ihnen überlassen, diesen Schlamassel aufzuräumen.

Aus der Datei /etc/group wurde die Gruppe gelöscht. Die Datei gehört jetzt zur unbestimmten Gruppe 502. Diese Zahl ist wird Gruppen id oder guid genannt. Wir können das dazu verwenden, etwas aufzuräumen. Verwenden Sie den Befehl find, um alle Dateien mit der guid 502 ausfindig zu machen.
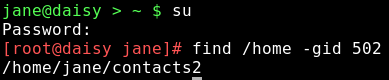
Wie erwartet finden wir nur die eine Datei, die wir verändert hatten, aber selbst wenn es sehr viele Dateien wären, es wäre ein Leichtes
chown :jane Dateiname
die Verwaisung aufzuheben.
Wenn es aber hunderte Dateien wären, dann wäre es entmutigend, sie alle von Hand ändern zu müssen. Dafür könnten wir eine Schleife verwenden. Darüber werden wir bald sprechen.